Dear friends,
👋 Welcome to this week's curated article selection from BestBlogs.dev!
🚀 In this edition, we spotlight the latest breakthroughs, innovative applications, and industry dynamics in the AI field, bringing you the essence of model advancements, development tools, product innovations, and market strategies. Let's dive into the cutting-edge developments in AI!
🧠 AI Models and Technologies: Performance Leaps, Capability Expansions
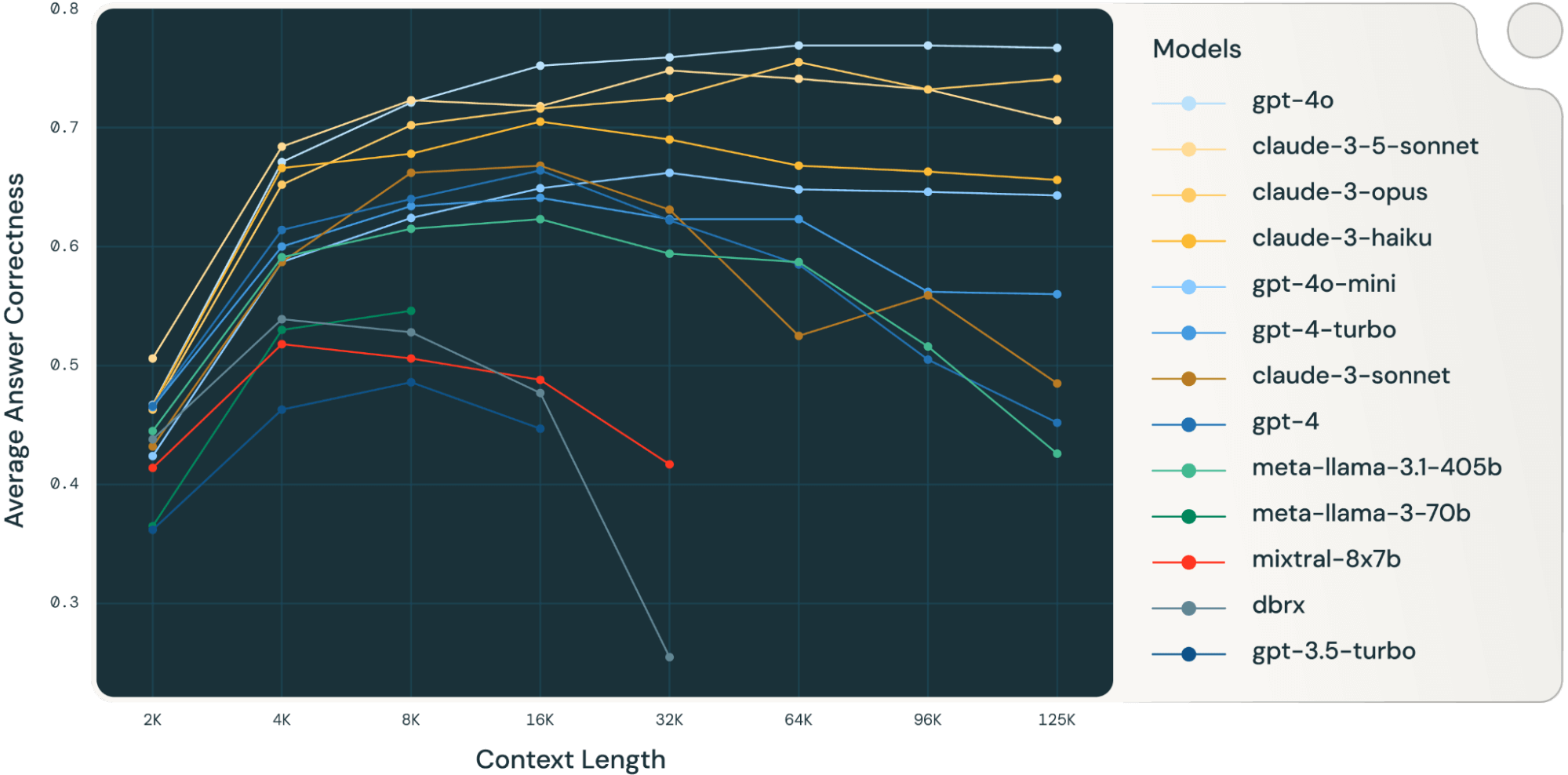
- xAI unveils Grok-2, a large language model (LLM) ranking fourth on the LMSYS Chatbot Arena, closely trailing GPT-4o in performance.
- Zhipu AI introduces GLM-4-Long, boasting a 1M token context length and competitive pricing, ideal for extensive document processing.
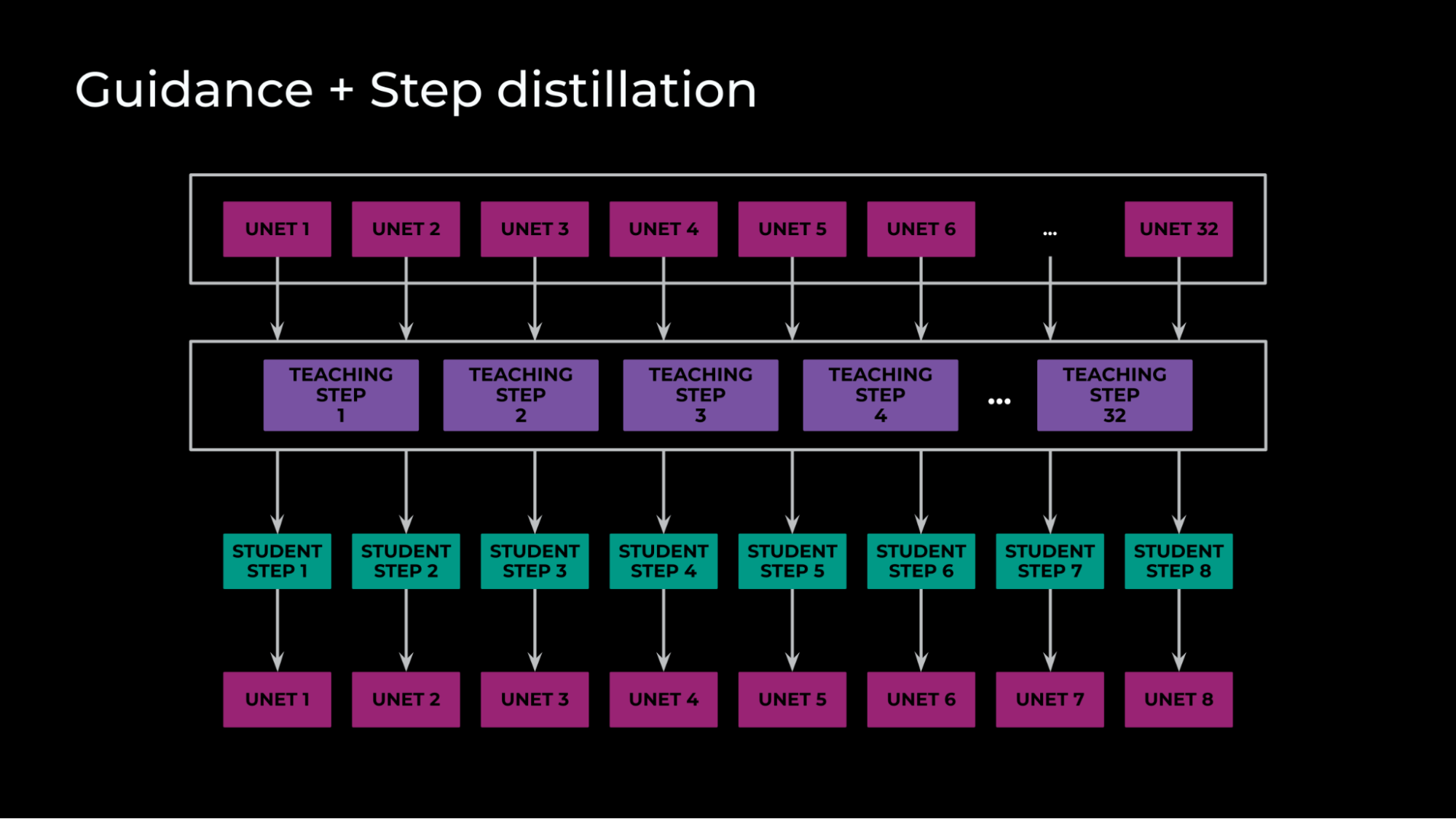
- Mianwei AI's MiniCPM-V 2.6 achieves state-of-the-art (SOTA) performance in multimodal tasks, surpassing GPT-4V in single-image, multi-image, and video understanding on edge devices.
💻 AI Development and Tools: Boosting Efficiency, Slashing Costs
- Claude, Google, and others roll out long text caching features, dramatically reducing processing costs by up to 90% for lengthy texts.
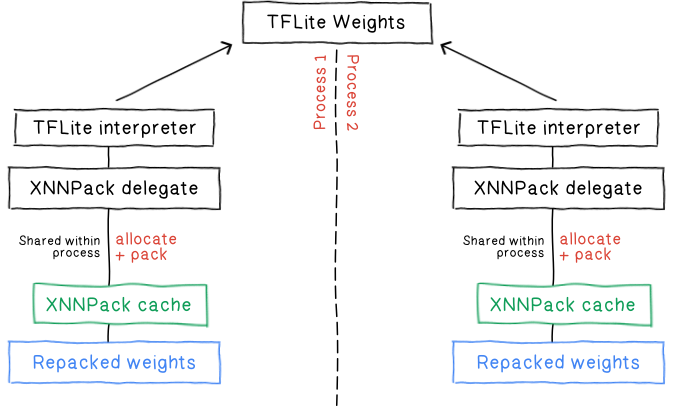
- TensorFlow Lite enhances LLM inference on edge devices, significantly improving performance and energy efficiency.
- GitHub introduces Copilot Autofix, tripling the speed of code security fixes and markedly enhancing developer productivity.
🎯 AI Products and Applications: Innovations in Action, Enhanced User Experiences
- Google launches Gemini Live, showcasing advanced AI conversational capabilities and seamless multi-app integration on mobile devices.
- Cosine debuts Genie, an AI engineer outperforming peers in autonomous coding, bug fixing, and various development tasks.
- AI technologies are transforming news media, education, and child companionship, revolutionizing content creation, learning experiences, and user interactions.
🌐 AI Industry Dynamics: Navigating Opportunities and Challenges
- Industry experts, including Li Mu and Wang Hua, predict AI could generate opportunities ten times greater than mobile internet, while acknowledging challenges like tech bubbles and data security.
- AI hardware (e.g., AI glasses) and embodied intelligence emerge as promising research areas, poised for explosive growth in the next 3-4 years.
- Mixture of Experts (MoE) models gain traction as a solution to enhance efficiency and address computational resource constraints in large AI models.
🔗 Intrigued to learn more? Click through to read the full articles and gain deeper insights!