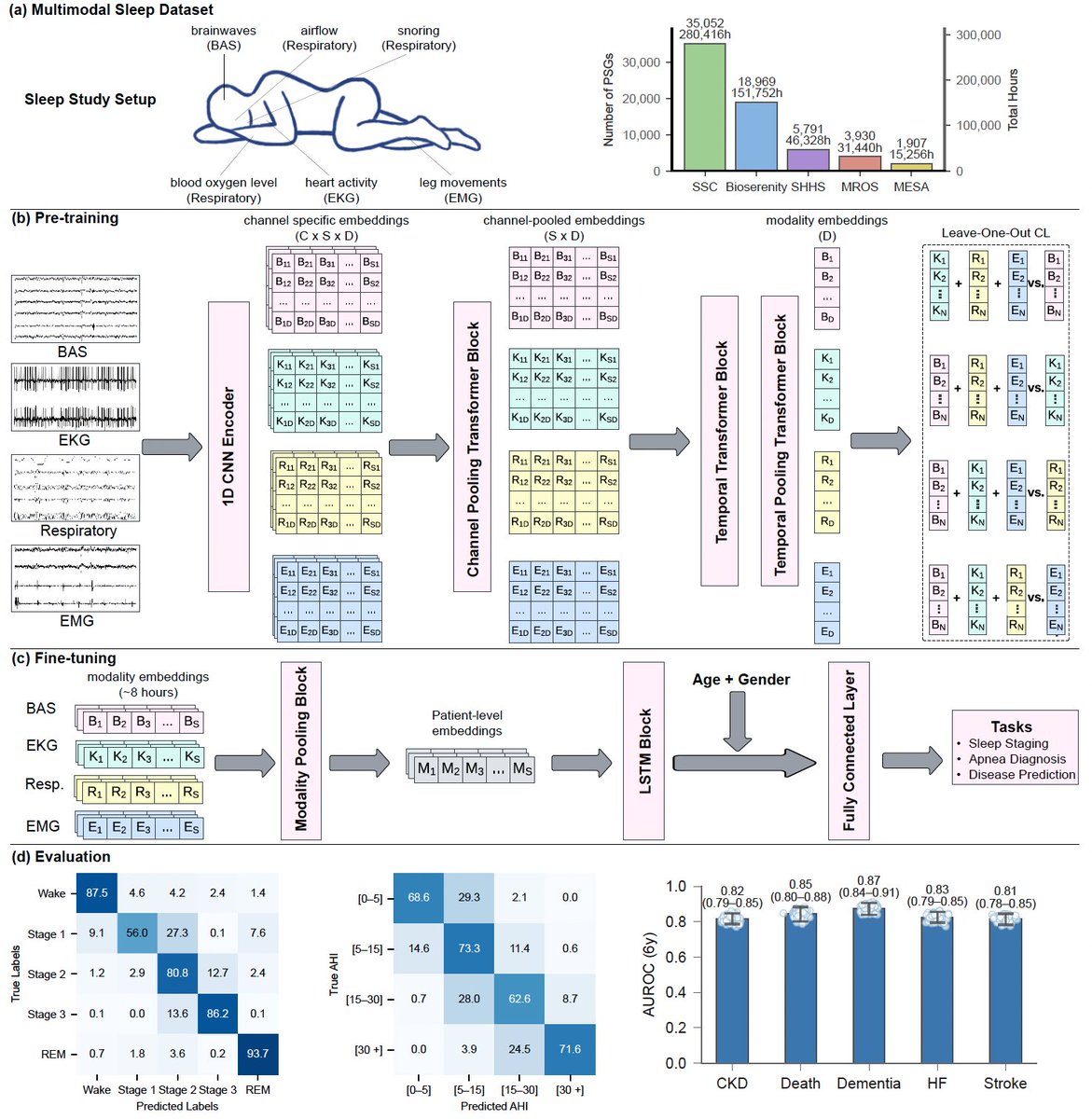
Stanford AI Lab
@StanfordAILab · 2天前我们的最新研究 TTT-E2E,标志着LLM记忆的新时代。
现在,模型能在部署后继续训练:它将上下文作为训练数据,直接更新自身权重,从而实现从海量经验中持续学习。
与 @NVIDIAAI 和 @AsteraInstitute
Karan Dalal
@karansdalal · 2天前LLM memory is considered one of the hardest problems in AI.
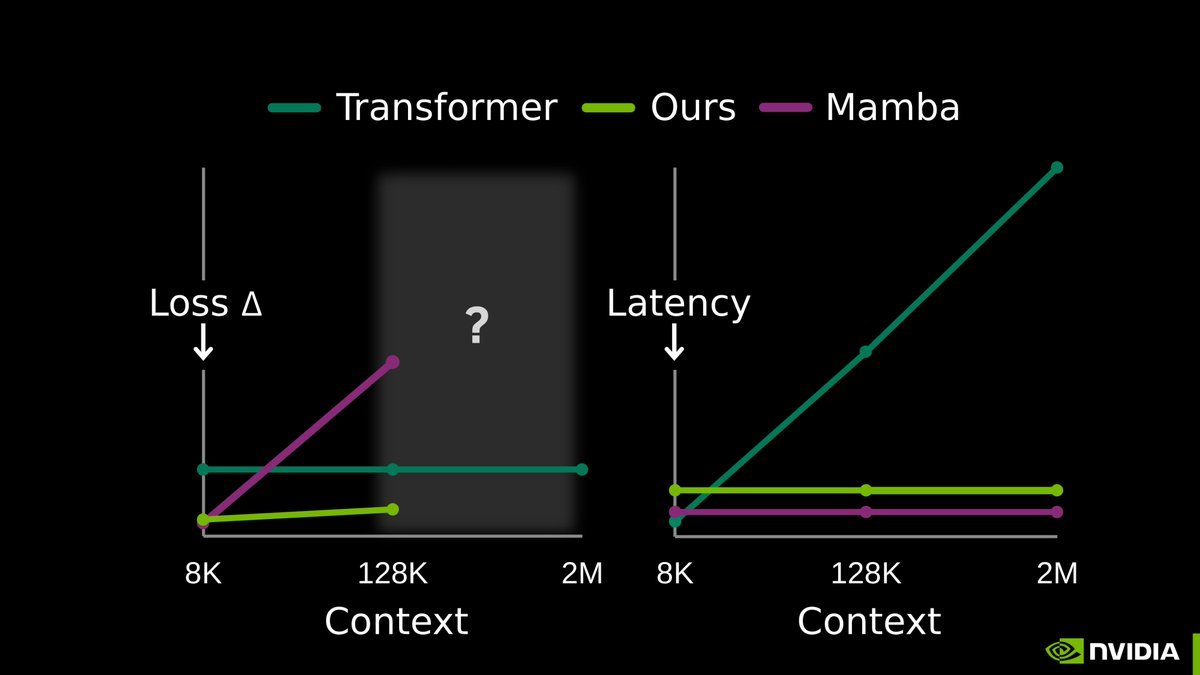
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: nvda.ws/4syfyMN
Arxiv: arxiv.org/abs/2512.23675
This has been over a year in the making with @arnuvtandon and an incredible team.
36
118
780
10.7万
3
5
12
7
5