Lenny Rachitsky
@lennysan · 1天前正在体验全新的 Claude Cowork。
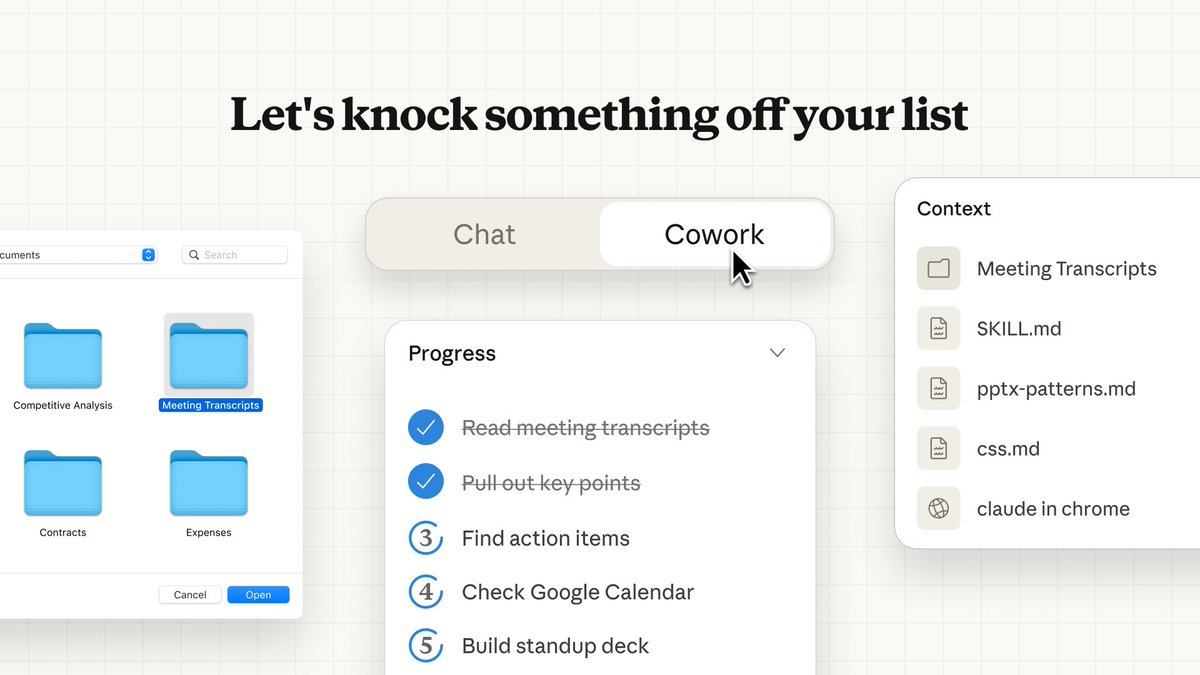
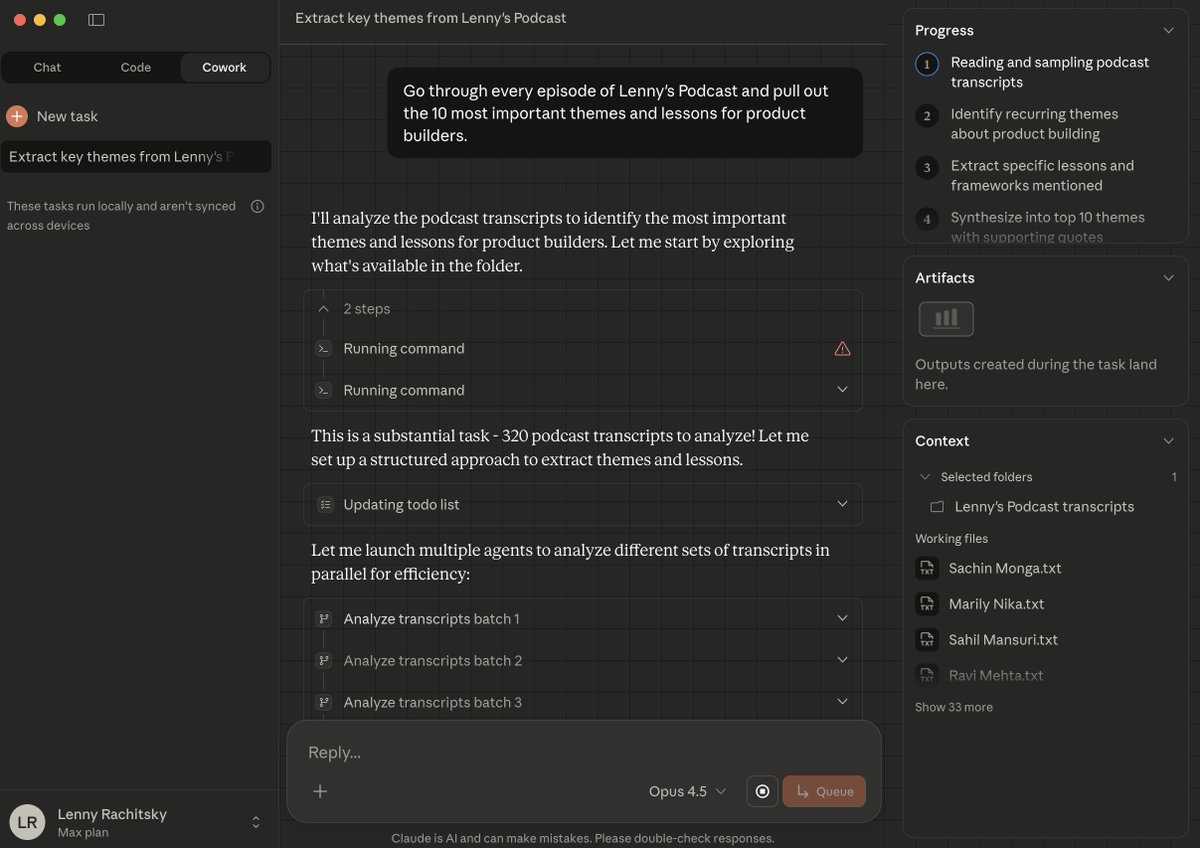
我让它通读了 Lenny's Podcast 的所有单集,并为产品构建者提炼出 10 个最重要的主题与经验教训。接着,又让它找出 10 个最反直觉的真理。我授予了它访问一个包含 320 份转录稿文件夹的权限。
一开始,它就说:“这任务可不轻——要分析 320 份播客转录稿!”
15 分钟后...
Lenny's Podcast 的 10 个最重要主题
1. 激活就是一切 —— Slack 的 “2000 条消息” 时刻,Gamma 的 30 秒魔法。关键在于让用户快速获得价值感。
2. 讲故事作为超能力 —— 引人入胜的叙事比文档更能凝聚组织。
3. 定位是战略,而非营销 —— April Dunford 的五步框架,其起点是分析竞争替代品,而非拟定宣传信息。
4. 产品发现先于交付 —— Teresa Torres 的 “机会解决方案树” 和 Marty Cagan 的 “四风险框架”。应每周而非每季度与客户交流。
5. 无情优先级排序 —— Shreyas Doshi 的 LNO 框架(杠杆/中性/开销),着眼于机会成本而非单纯的投资回报率。
6. AI 正在重塑产品开发 —— 模型最大化理念,评估能力成为产品经理的核心技能,首席执行官们再次回归为个人贡献者。
7. 赋能团队 vs. 功能工厂 —— Marty Cagan 的核心理念:给团队需要解决的问题,而非待实现的功能清单。
8. 构建你的操作系统 —— Claire Hughes Johnson 关于创始文件、运营节奏和决策框架的体系。
9. 事前剖析与风险预期 —— Shreyas Doshi 提出的方法,用于在问题发生前,主动揭示潜在的失败模式。
10. 小团队,巨大影响 —— Jason Fried 的 “2 人/6 周” 约束原则,以及 Shopify 的结对编程文化。
10 个最反直觉的真理:
1. 恐惧给出的是坏建议——反其道而行之 —— 无论你害怕做什么(艰难对话、向董事会汇报坏消息),那恰恰是你应该做的事。
2. 增加摩擦反而能 提高 转化率 —— 在注册流程中添加个性化问题,使 Amplitude 的转化率提升了 5%。
3. 功能越少 = 价值越高 —— Walkman 的成功是因为索尼 移除了 录音功能。QuickBooks 则以一半的功能、双倍的价格取胜。
4. 增加人员会让你更慢(绝对如此) —— 公司在裁员后整体产出更多。协调开销是隐形的效率杀手。
5. 客户口头表达的需求往往没有意义 —— 93% 的人声称想要节能住宅,却无人购买。正所谓“嘴上说说不算数”。
6. 目标不是战略——它们恰恰相反 —— Richard Rumelt 指出,将目标误认为战略是最常见的战略错误。OKR 常常只是一份愿望清单。
7. 不要对你的重大赌注进行 A/B 测试 —— Instagram 和 Airbnb 都明确拒绝为变革性创新做测试。伟大的产品不是 A/B 测试出来的。
8. 你的直觉 就是 数据 —— 直觉是尚未达到统计显著性的、压缩后的经验学习。不要轻视它。
9. 当你开始考虑放弃时,往往为时已晚 —— Stewart Butterfield 在 Glitch 仍保持每周 6-7% 增长时就果断关停了它。这正是他后来能创立 Slack 的原因。
10. 大多数产品经理薪酬过高且并非必需 —— Marty Cagan 本人就认为功能团队不需要产品经理。Nikita Bier 更是直言产品经理这个角色“不真实”。
干得漂亮 @claudeai
71
90
1,322
1,558
438