GitHub
@github · 1周前这 12 个开源团队带来了十足的创造力、精湛的工程技艺,以及那些令人跃跃欲试的演示,正是它们让 GitHub Universe 如此特别。
这里是他们过去一年展示的内容,以及你如何加入 2026 年的下一届活动。⬇️
github.blog/open-source/ma…
11
16
73
11
18
这 12 个开源团队带来了十足的创造力、精湛的工程技艺,以及那些令人跃跃欲试的演示,正是它们让 GitHub Universe 如此特别。
这里是他们过去一年展示的内容,以及你如何加入 2026 年的下一届活动。⬇️
github.blog/open-source/ma…
LLM 排行榜 (https://t.coopenrouter.ai/rankings
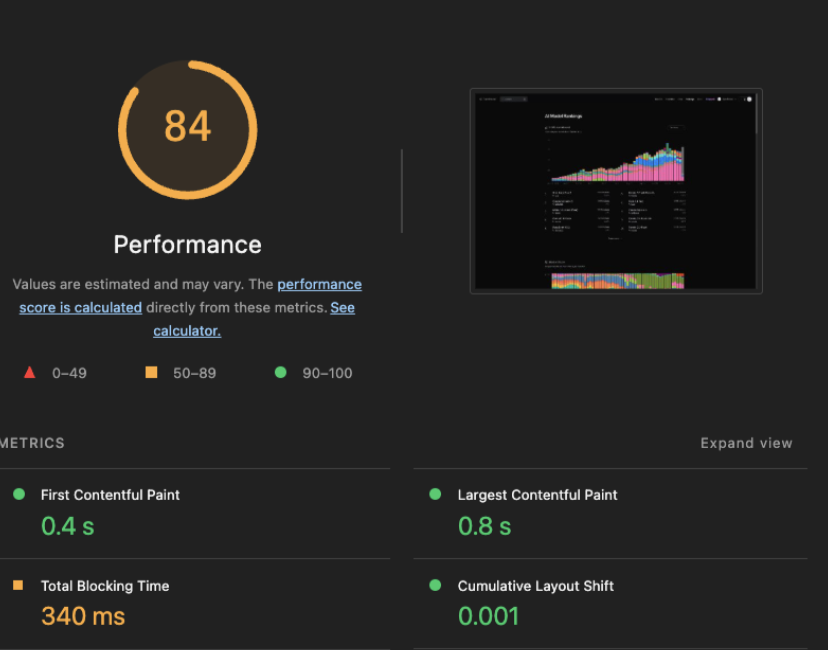
通过使用基于交叉观察器的懒加载结合代码分割,将总阻塞时间 (TBT) 缩短了一半
主流 LLM 虽然都支持结构化输出,但在处理海量复杂文档时,往往难以零样本、高精度地提取其中的大量信息。
为此,我们发布了一篇新教程,旨在帮助您实现从复杂文档中进行零样本、大规模重复结构化信息的提取。
例如,假设您有一个包含 100 份简历的文件,需要为每位候选人提取其信息;或者您手头有一整套财务报表需要处理。
针对这类场景,您需要一个多步骤智能体工作流。该工作流能够:1) 识别文档边界 ✂️;2) 智能地从文档的特定部分提取目标信息 📝;3) 将提取的结果整合起来 🧵。
其核心是运用我们的 LlamaSplit 功能将文档切分为相关的“子块”,再通过 LlamaExtract 从每个子块中提取格式统一的结构化输出。
developers.llamaindex.ai/python/cloud/l…

我们经常遇到这样一个问题:包含多个重复内容片段的长文档。例如,一份简历册可能包含封面页、几页学生课程介绍,然后是连续排列的多份个人简历。
现在,你可以构建一个智能简历处理代理,自动从这些重复内容中提取结构化数据。其核心原理是:使用 LlamaSplit 识别每份独立内容(如单份简历)的起止位置,再使用 LlamaExtract 进行结构化数据提取。
具体步骤如下:
📄 将 PDF 格式的简历册上传至 LlamaCloud,利用 LlamaSplit 自动对页面进行分类,将个人简历与课程介绍、封面页分离开来。
🤖 使用带有自定义模式的 LlamaExtract 从每份简历中提取结构化信息,例如姓名、联系信息、教育背景、工作经验和技能等。
⚡ 通过 LlamaAgent 工作流来编排整个处理流程。
🔍 处理真实的简历数据,获得带有置信度分数的结构化输出,这些数据可直接用于过滤、搜索及候选人匹配等系统。
该教程以一份 NYU 简历册为例,展示了从单独的 API 调用到完整的自动化工作流实现。
查看完整教程:developers.llamaindex.ai/python/cloud/l…

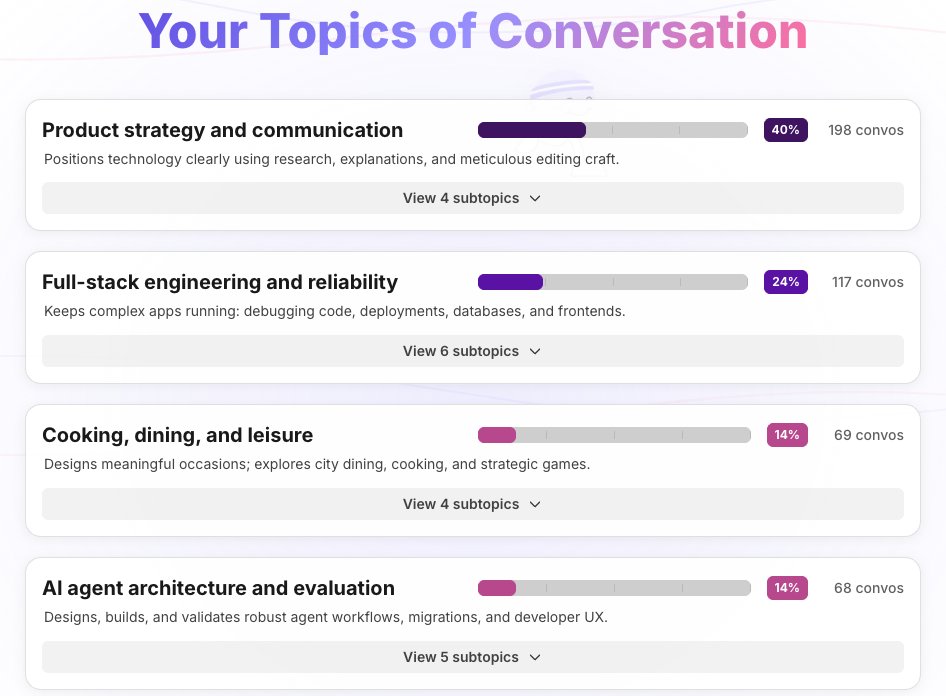
🎉 AI Wrapped 2025
今年你到底用 ChatGPT 和 Claude 做了些什么呢?(老实交代!)
LangSmith Insights 智能体可以分析你的对话历史,并找出那些你可能从未察觉的模式、趋势和有趣的聚类。
快来用你的数据试试看吧:wrapped.langchain.com
萨班斯-奥克斯利法案审计不必耗费你团队的精力,也无需占用你的预算。
Oxus 是专为萨班斯-奥克斯利法案审计设计的 AI 原生自动化平台。它能在数分钟内将原始证据转化为可供审查的结果,每年为你节省数百万美元的外包成本。
恭喜发布!
ycombinator.com/launches/P5u-o…

· ✶ ✢ ✽ 令人惊艳 (在 @vercel AI Gateway 上)
You can now use Claude Code with Vercel AI Gateway.
Route requests through AI Gateway to track usage and spend, view traces in observability, and centralize controls for models and providers.
Set it up in seconds ↓
vercel.com/changelog/ai-g…
VINO
一个具有交错全模态上下文的统一视觉生成器