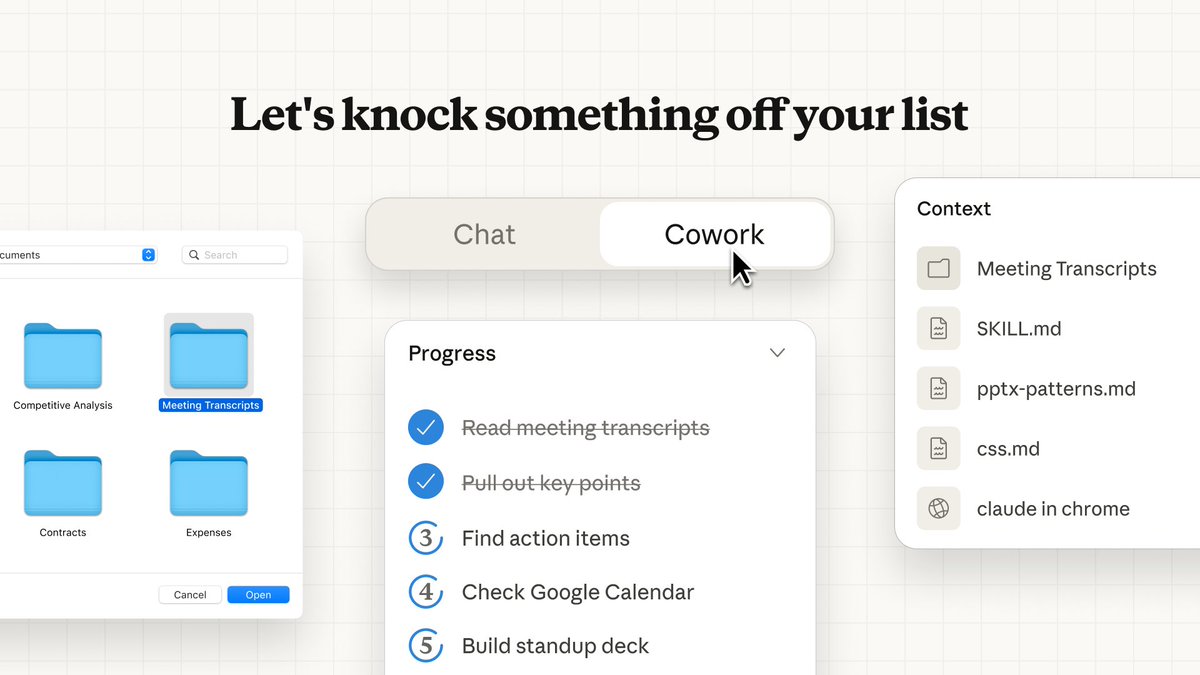
MIT 研究人员提出了递归语言模型。
请记住,到 2026 年,你会频繁听到它的名字。
这有什么意义呢?
试想一下,如果大语言模型能处理的输入长度,是其上下文窗口的 100 倍,会怎样?
上下文长度是一个硬性约束。
你可以通过修改模型架构来扩展它,但总有一个上限。大多数现有方法要么试图在有限窗口内塞入更多信息,要么对超出的部分进行压缩。
这项新研究另辟蹊径。与其正面硬刚上下文限制,不如通过巧妙的程序逻辑来绕过它。
递归语言模型将超长提示词视为一个外部环境。模型可以审视整个提示,将其分解为多个部分,然后在各个片段上递归地调用自身进行处理。这实质上是在推理阶段,通过递归来实现对超长上下文的处理能力扩展。
其核心思想是:不必强求一次性通过注意力机制处理所有信息,而是让模型通过多次递归调用,策略性地对信息进行分区和处理。
结果令人印象深刻。RLMs 成功处理了超出模型原始上下文窗口两个数量级的输入。一个仅有 8K 上下文窗口的模型,可以有效应对长达 800K 标记的内容。
但真正令人惊讶的是:即使对于那些原本就能放入上下文窗口的较短提示词,RLMs 在四项不同的任务上也显著优于基础 LLM 和常见的其他长上下文处理方案。
这暗示了一个有趣的可能性:
也许,即使技术条件允许,对整个输入进行顺序注意力计算也并非总是最佳策略。对于某些任务而言,程序化的分解和递归处理可能在本质上更为优越。
与其他的长上下文处理方法相比,该方法的单次查询成本相当甚至更低。
上下文长度的限制约束了智能体的能力边界。要处理整个代码库、长篇文档或冗长的对话历史,通常需要额外的变通方案。RLMs 提供了一种通用的推理策略,有望将上下文限制从一个“硬约束”转变为“软约束”。