meng shao
@shao__meng · 4天前[Engineering at Anthropic] 揭秘 AI Agent 的评估:好的评估是 Agent 走向生产力的唯一途径,建立一套自动化的、覆盖“过程”与“结果”的评估闭环至关重要 ⚠️
anthropic.com/engineering/de…
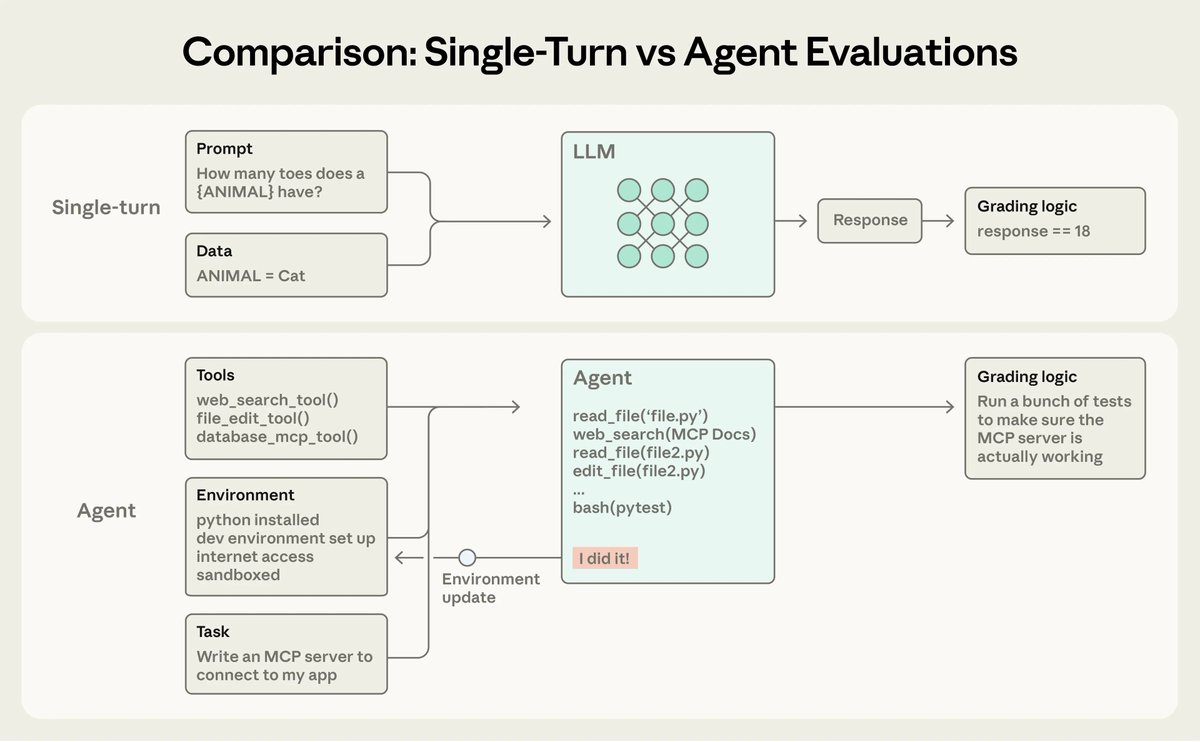
核心挑战:为什么 Agent 的评估很难?
Agent 的强大源于其“灵活性”,但这恰恰是评估的噩梦:
· 多轮耦合:一个错误可能会在多轮对话中累积,导致最终失败。
· 非确定性:即使输入相同,Agent 的路径也可能不同。
· “创意型”成功:有时 Agent 发现了一个人类未预料的捷径(比如通过政策漏洞解决问题),虽不符合预期路径,但实际上完成了任务。
· 环境依赖:Agent 需要操作数据库、文件系统或浏览器,评估需要一个受控的沙盒环境。
评估体系的“四梁八柱”
Anthropic 提出了一个标准的 Agent 评估术语库:
· 任务:单个测试用例。
· 评判器:评分逻辑(包括代码判定、LLM 判定和人工判定)。
· 轨迹/轨迹追踪:Agent 执行过程的完整记录,包括思考过程和工具调用。
· 结果:任务结束后的最终环境状态(例如:数据库里是否真的存入了订单,而不仅仅是 Agent 说“订好了”)。
· Agent 脚手架:运行 Agent 的系统框架(如 Claude Code)。
三种评判器的优劣对比(建议组合使用)
· 基于代码:最快、最便宜、最客观。适用于判断代码是否跑通、单元测试是否通过、字符串是否匹配。缺点是死板。
· 基于模型:灵活、能捕捉细微差别。通过定义好的 Rubric(评分量表)让更高级的模型给 Agent 打分。缺点是存在非确定性。
· 人工评判:黄金标准。用于校准模型评判器,但成本高、速度慢。
关键评估指标:pass@k vs pass^k
这是衡量 Agent 稳定性的两个核心维度:
· pass@k(k 次尝试中至少成功一次):衡量 Agent 的“天花板”能力。只要能做出来就算赢。适用于代码生成等场景。
· pass^k(k 次尝试全部成功):衡量 Agent 的“可靠性”。适用于客服、金融等对一致性要求极高的场景。
三类典型 Agent 的评估策略
· Coding Agent:核心在于“运行结果是否正确”。使用单元测试、Lint 检查和静态分析。
· Conversational Agent:侧重于流程遵循。使用 LLM 评判器检查是否遵守了“不要给折扣”等业务规范。
· Computer Use/Browser Agent:侧重于环境变更。检查执行后的系统状态(如 DOM 元素变化、API 返回值)。
实操建议:如何从零构建?
不要等 Agent 完美了才做评估,而是应该:
· 早期(0->1):从 20-50 个真实失败案例开始,建立初始测试集。
· 中期(迭代):同时运行能力评估(挑战更难的任务)和回归评估(确保旧功能不退化)。
· 后期(规模化):将高通过率的能力测试“提拔”为回归测试,并持续通过 A/B 测试对比线上表现。

0
0
0
1
0