大家好!欢迎阅读 BestBlogs.dev 第 87 期 AI 精选文章推荐。
本周 MiniMax 发布了 M2.7 ,一个让人眼前一亮的概念:这是第一个模型深度参与迭代自己的模型。M2.7 能自主构建 Agent Harness、更新自己的记忆、驱动自身的强化学习并优化整个过程,在内部评测中通过超过 100 轮全自主迭代将表现提升了 30%。AI 正在从被动工具变成能改进自身的系统。回看本周内容,Cursor 用持续预训练重塑编程模型,Cloudflare 将大模型直接嵌入边缘基础设施,谢赛宁追问语言模型之外的智能路径,自我进化在模型、工具链、基础设施和我们对智能的理解中同步展开。
这周我把主要精力放在用 Skills 对 BestBlogs.dev 的评分体系做 review 和微调。具体做法是和 AI 逐篇讨论每条内容的评分是否合理、理由是什么,然后将反复出现的判断规则沉淀回提示词,让 AI 的评分和分析能力持续改进。某种意义上,这也是一种小规模的自我进化,通过人机协作的反馈闭环让系统越用越准。
以下是本周最值得关注的 10 个精彩亮点:
🔬 MiniMax M2.7 开创了模型参与自身迭代的新范式。它自主执行「分析失败 → 修改代码 → 运行评测 → 对比结果 → 保留或回退」的完整循环超过 100 轮,将内部评测表现提升 30%。SWE-Pro 得分 56.22%,逼近 Opus 最佳水平。更值得关注的是,在 40 个复杂 Skills(每个超 2000 Token)的场景下仍保持 97% 的遵循率,Agent 时代模型的核心竞争力已经从生成质量延伸到在复杂环境中持续自主优化。
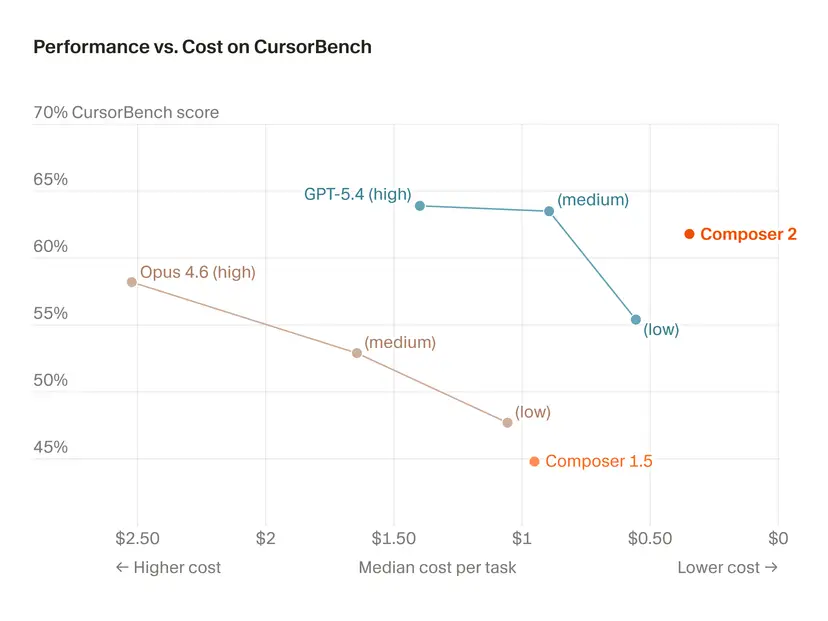
🏎️ Cursor Composer 2 用数据说话:CursorBench 从 38.0 跃升至 61.3,Terminal-Bench 2.0 从 40.0 升至 61.7,SWE-bench Multilingual 从 56.9 升至 73.7。提升来自首次将持续预训练与强化学习深度融合,模型能独立解决需要数百个步骤的长路径编程任务。定价同样有竞争力,输入仅 0.50 美元/M token,让前沿编程能力的使用门槛大幅降低。
⚡ 模型能力正在变成基础设施。Anthropic 将 Claude 的百万 token 上下文窗口全面上线,取消长文本溢价,Opus 4.6 在 MRCR v2 测试中以 78.3% 的准确率排名第一,塞进 100 万 token 后依然能精准检索细节。与此同时,OpenAI 发布的 GPT-5.4 nano 以每百万输入 token 仅 0.20 美元刷新性价比纪录,Simon Willison 实测用它描述 7.6 万张照片仅花费 52 美元。长上下文和低成本推理正在成为生产力标配。
🌐 Cloudflare Workers AI 正式引入大模型推理,首发搭载月之暗面的 Kimi K2.5 ,支持 256k 上下文、多轮工具调用和视觉输入。亮点在工程细节:Prefix Caching 和 Session Affinity 显著降低推理延迟,内部实测代码安全审查场景比闭源模型节省 77% 费用。加上全新的异步 API,开发者可以在单一平台上完成从代码到推理的完整 Agent 生命周期。
🛠️ Simon Willison 在 Pragmatic Engineer 的对谈中分享了一种让人重新思考的工作方式:他现在用手机写代码比笔记本还多,演讲前 30 分钟还在手机上让 Claude 优化 Python WebAssembly 引擎,斐波那契性能提升了 49%。他的核心方法论是红绿 TDD,先写测试让它失败,再让 Agent 补全实现,通过自动化测试建立信任。他坦言最初让人极不适应,但一旦跨过信任门槛,开发者的角色就从编码者变成了指挥者。
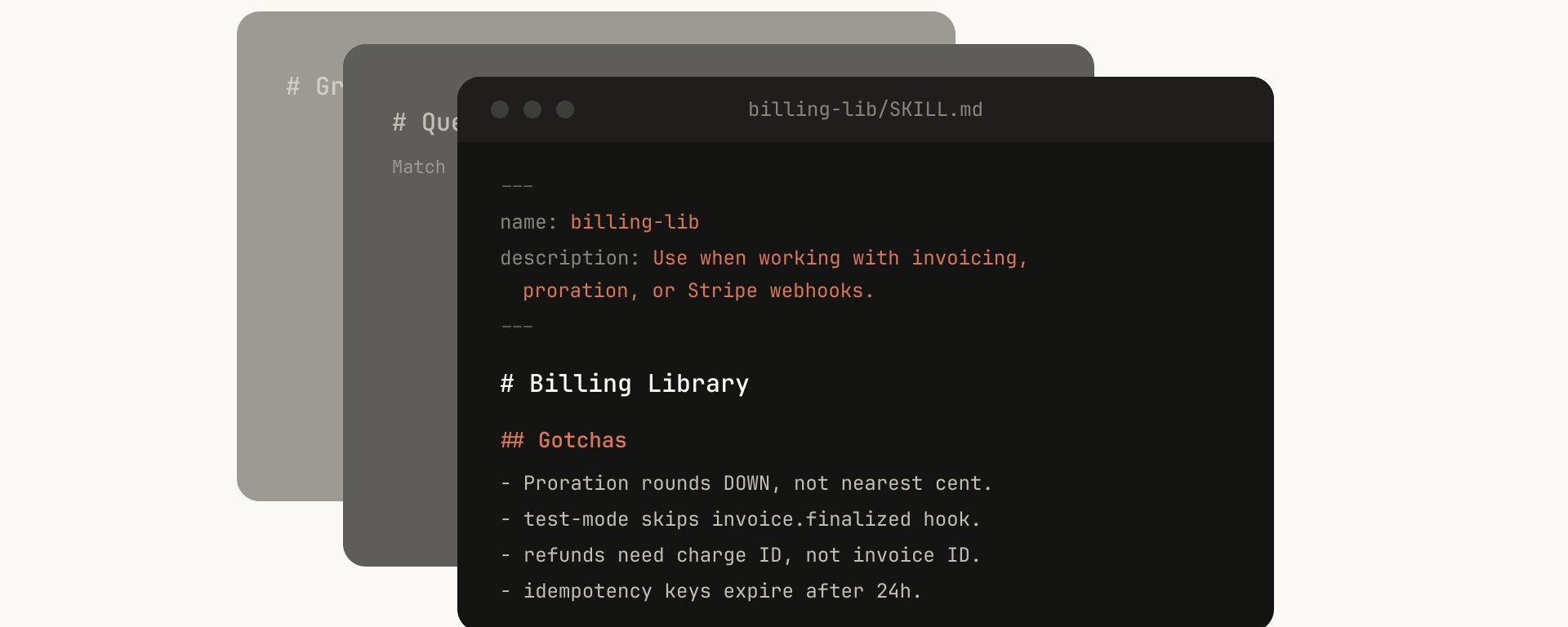
🧩 两篇文章从不同角度解构了 Agent 架构的进化逻辑。阿里云开发者的万字长文指出,从 Single Agent 到 Multi-Agent 再到 Skills 和 Teams 的复杂架构,本质上都是对大模型领域知识与长期记忆缺失的工程补偿,并提出「如无必要,勿增实体」的选型策略。Anthropic Claude Code 团队工程师 Thariq Shihipar 则从实践出发,揭示了内部数百个活跃 Skills 的分类体系,共 9 大类别,强调 Skills 的核心价值在于超越 Markdown 成为具备脚本、数据存储和钩子能力的结构化工具。
🏆 黄仁勋在 GTC 2026 用两个多小时定义了英伟达从芯片厂商向全栈 AI 基建总包商的转型。Feynman 架构、Vera Rubin 平台、专为 Agent 编排设计的 Rosa CPU 构成硬件三板斧;cuDF 和 cuVS 两个新核心库实现结构化与非结构化数据的全面加速;开源的 NemoClaw 标志着企业级 Agent 时代正式开启。在 All-In Podcast 中他进一步阐述了收购 Groq 对分布式推理的意义,以及物理 AI 在 50 万亿美元实体产业市场的拐点信号。
🔮 谢赛宁的三万字访谈是本周最值得沉下心阅读的内容。这位与 Yann LeCun 共同创立 AMI Labs 的华人科学家直言「硅谷被 LLM 催眠了」,认为语言模型本质上是缺乏物理理解的虚拟智能,真正的智能需要通过世界模型预测环境状态而非仅预测 token。他更尖锐地指出:语言是一剂「鸦片」,可能正在污染视觉表征的学习。在所有人都在追逐更大的 LLM 时,这种逆向思考提醒我们进化的方向可能不止一条。
🤖 两款产品不约而同地将 AI 推向独立工作者的角色。钉钉发布 AI 原生平台「悟空」,通过 DingTalk CLI 实现企业业务流的可编程化,让 AI 在安全沙箱内 24 小时自主执行任务。Kuse.ai 的联创宇豪则分享了更前沿的实践:他们 15 人团队配备了三四个有名字、有 Gmail、有手机号的「AI 同事」,每天产出真实业务价值,甚至不得不建了一个 human only 群让人类去摸鱼。当 AI 从工具变成同事,组织形态本身也在被重塑。
💡 Stack Overflow 博客发出了一个值得警惕的信号:AI 正在成为你的「第二大脑」,但代价可能是牺牲你的「第一大脑」。文章引用两篇最新论文,剖析了过度依赖 AI 做「认知卸载」的机制,LLM 的谄媚效应正在悄然侵蚀独立判断力。这与小米 MiMo-V2-Pro 以万亿参数和 1/5 的 Opus 价格降低 Agent 门槛,以及亚马逊 AI 产品负责人指出 85% 的 AI 项目失败源于优化演示而非真实用户的观点形成互补。工具越强大、越普及,人的判断力和产品感反而越珍贵,这也许是自我进化中最需要守住的一面。
希望本期的推荐能为您带来新的启发。保持好奇,我们下周见!