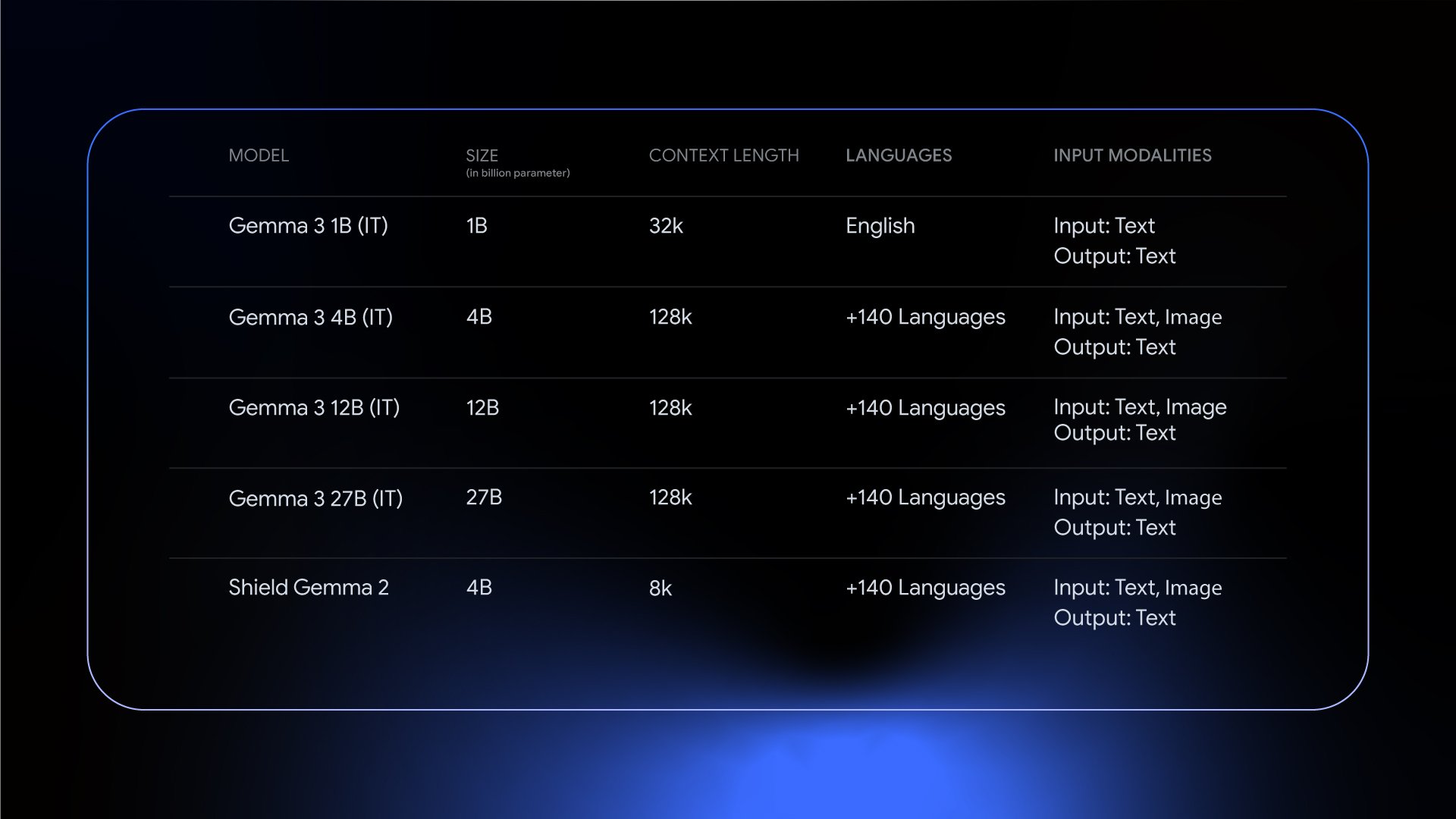
Google DeepMind introduces Gemma 3, the latest open model built upon Gemini 2.0, offering improved performance and multilingual support for over 140 languages. Gemma 3 features multimodal capabilities for analyzing images, text, and short videos, and an expanded 128k-token context window with function calling for task automation. Outperforming Llama-405B and others while fitting on a single GPU or TPU, Gemma 3 introduces quantized versions for efficiency. Alongside Gemma 3, Google launches ShieldGemma 2, an image safety checker. Gemma 3 integrates with tools like Hugging Face Transformers, Ollama, and NVIDIA GPUs and is optimized for Google Cloud TPUs. The Gemma 3 Academic Program provides cloud credits for research, expanding the Gemmaverse community.