👋 亲爱的读者朋友们,欢迎阅读本期 AI 领域精选文章!
本期,我们精心挑选了 30 篇人工智能领域的优质文章,为您深度剖析 AI 技术的最新突破与发展趋势。本周,大语言模型生态持续繁荣 ,Google、OpenAI 等科技巨头纷纷发布更强大、更易用的模型,加速 AI 技术进程。此外,AI Agent 技术 、多模态应用 以及安全可观测 等领域也迎来诸多进展。让我们紧随 AI 浪潮,一同探索本周的精彩内容!
本周亮点:
-
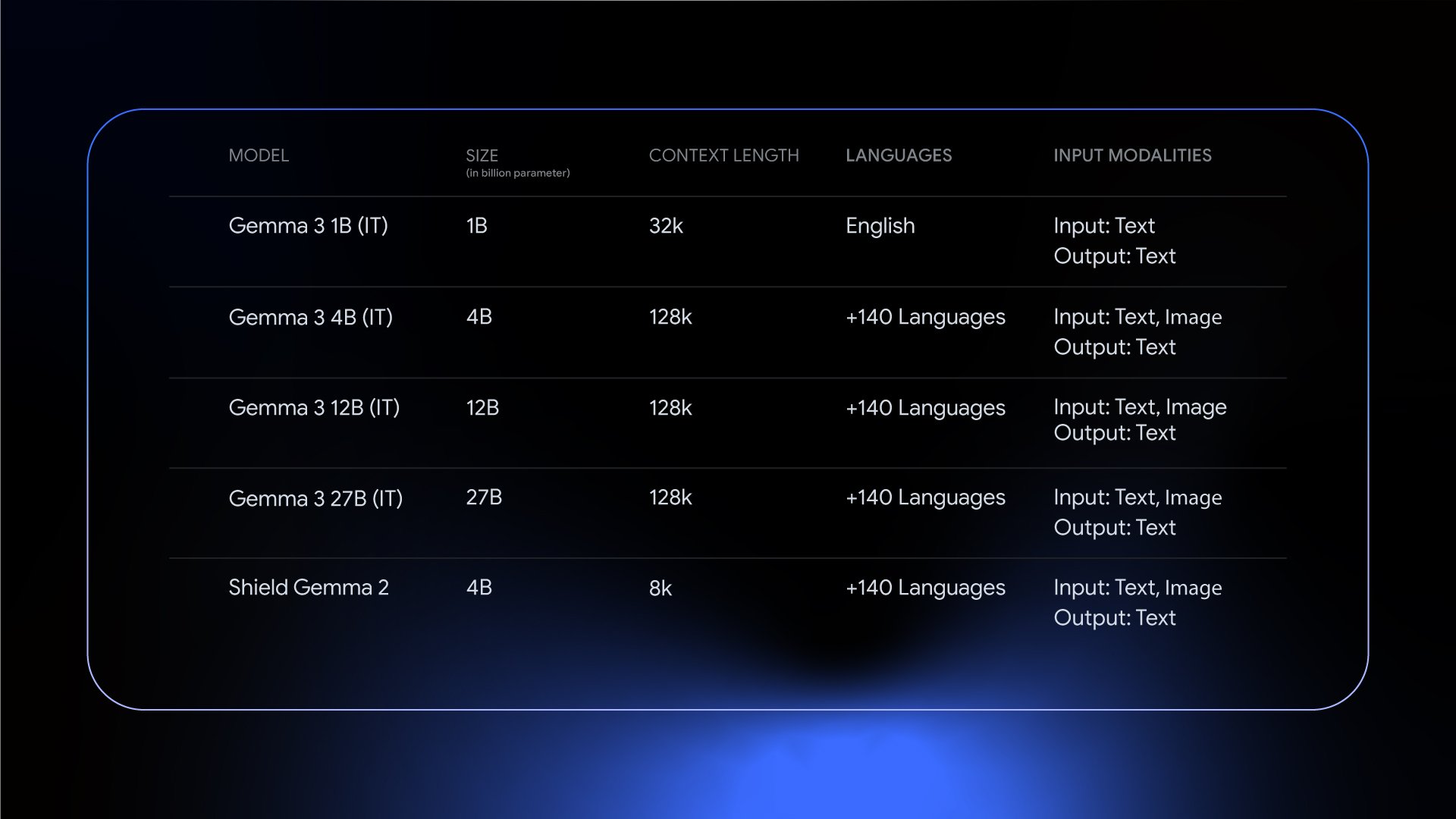
Gemma 3 发布:单 GPU 可运行的最强开源模型 : Google DeepMind 发布 Gemma 3 开源模型系列,基于 Gemini 2.0 技术,提供 1B 至 27B 多种尺寸选择,单 GPU 即可高效运行。支持 35+ 种语言、多模态推理及函数调用,大幅降低使用门槛,加速开源 AI 普及。
-
Gemini 2.0 Flash 原生图像生成开放实验 : Google 开放 Gemini 2.0 Flash 原生图像生成功能,开发者可率先体验多模态大模型的强大图像创作能力,尤其在文本渲染和世界知识理解方面表现出色,为多模态 AI 应用开辟新方向。
-
OpenAI 智能体工具链 Responses API & Agents SDK 发布 : OpenAI 重磅推出 Responses API,统一 Chat Completions 和 Assistants API 接口,内置网络搜索、文件搜索等实用工具,并发布开源 Agents SDK,四行代码即可构建智能体应用,大幅简化 Agent 开发流程。
-
Open-Sora 2.0:开源视频生成模型成本革命 : 11B 参数的 Open-Sora 2.0 开源模型,实现媲美 30B 模型的视频生成效果,训练成本仅 20 万美元,大幅降低 10 倍。模型权重、代码、流程全面开源,推动高质量、低成本视频生成技术发展。
-
腾讯混元快思考 Turbo S 模型:推理速度大幅跃升 : 腾讯混元发布新一代旗舰模型 Turbo S,首字响应时间降低 44%,吞吐提升 100%,API 定价大幅降低。采用 Hybrid Mamba Transformer 架构,兼顾线性复杂度和全局建模能力,提升用户体验并降低使用成本。
-
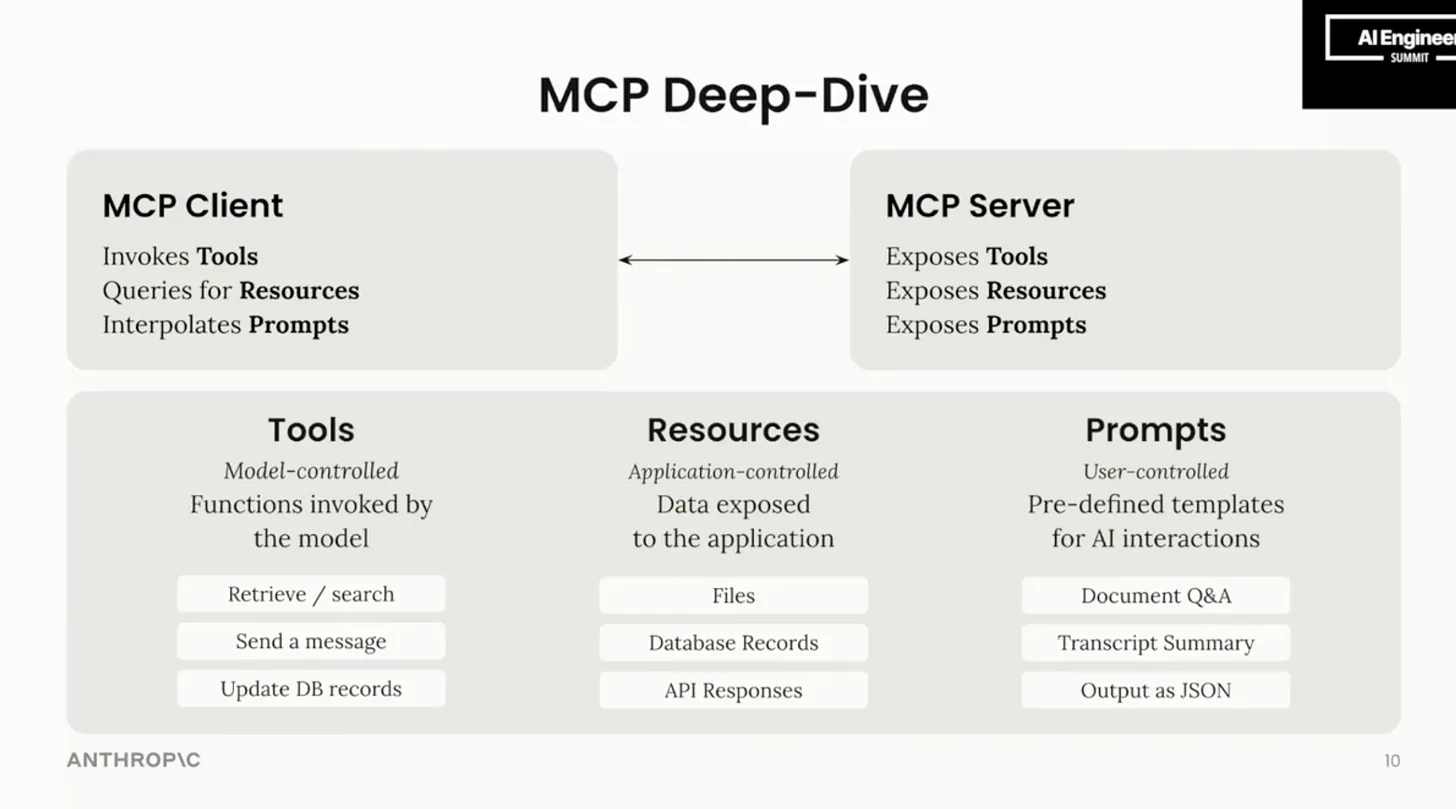
模型上下文协议 (MCP):引领智能体开发新范式 : Anthropic 等力推 MCP 协议,旨在统一 AI 模型与外部工具的连接标准,大幅简化 Agent 集成复杂度,被誉为 AI 领域的 "USB-C",有望成为智能体开发的关键基础设施。
-
长文本向量模型检索局限性: 4K Tokens 成瓶颈? : Jina AI 实验揭示,当前向量模型在处理超过 4K Tokens 长文本时,检索准确率显著下降,长文本理解能力面临挑战,引发对长文本检索技术的深入思考与改进需求。
-
Gemini 应用升级:多模态能力与用户体验再提升 : Gemini 应用迎来重大更新,搭载更强大的 2.0 Flash Thinking 模型,支持更长上下文窗口和文件上传,并推出个性化 Gems 功能,多模态能力和用户交互体验显著提升。
-
AI 笔记神器 NotebookLM:多场景应用保姆级教程 : Google AI 笔记工具 NotebookLM 功能持续增强,在文献梳理、速读学习、会议纪要等多种场景展现高效应用价值。保姆级教程助您快速掌握 NotebookLM 使用技巧,提升学习与工作效率。
-
LeCun 洞察: AI 发展需理解物理世界,突破语言限制 : LeCun 高度评价 DeepSeek 开源贡献,同时强调当前 AI 系统在理解物理世界方面仍显不足,认为 AI 发展需超越文本训练,理解真实世界的复杂性,为 AGI 发展指明新方向。
🔍 想深入了解这些精彩内容?欢迎点击对应文章链接,探索更多 AI 领域的创新与发展!让我们在快速迭代的 AI 浪潮中携手并进,共同迎接人工智能的无限未来。