大家好,欢迎阅读 BestBlogs.dev 第 57 期 AI 精选。
本周,开源大模型的竞争进入白热化阶段,通义和智谱相继发布旗舰模型,在推理、代码与智能体等多个维度刷新 SOTA 记录,进一步凸显了中国在开源领域的强劲势头。与此同时,从视频到 3D 世界生成,多模态技术持续突破。在应用层面,AI 浏览器和各类开发工具正加速迭代,而行业领袖们则不约而同地将目光投向了 AI 的下一个时代:经验学习与人机共生。
🚀 模型与研究亮点
- 🏆 通义千问在一周内连发三款开源模型,其 Qwen3 新推理模型不仅在多项测试中超越 OpenAI o4-mini ,还能展示详细的思考过程。
- 🤖 智谱发布专为智能体设计的开源旗舰模型 GLM-4.5 ,在推理、代码和智能体综合能力上达到 SOTA,并大幅优化了 API 调用成本与速度。
- 🎬 通义万相发布视频生成模型 Wan2.2 ,通过引入 MoE 架构和深度美学训练,旨在让每个像素都达到电影级质感。
- 🌍 腾讯混元开源首个兼容传统 CG 管线的 3D 世界模型 HunyuanWorld-1.0 ,能够生成可漫游、可交互的沉浸式 3D 场景。
- 🏛️ 一篇技术长文深入比较了 DeepSeek-V3 、Kimi K2 等八种现代 LLM 架构,系统性解析了多头潜在注意力、混合专家等前沿技术。
- 🗣️ 一期播客逐段讲解了 Kimi K2 的技术报告,并对照 ChatGPT Agent 等竞品,强调了将研究成果转化为稳定 Agent 产品的系统工程挑战。
🛠️ 开发与工具精粹
- ✍️ 如何告别意大利面条式的系统提示词?一篇文章提出用系统架构思维,从核心定义、交互接口等四个层次,结构化地设计提示词。
- 🖼️ Vercel 发布 AI SDK 5 ,通过重新设计的聊天体验和强大的智能体循环控制功能,简化了复杂 AI 应用的开发。
- 👨💻 AI 代码编辑器 Cursor 的技术揭秘,深入介绍了其如何通过超低延迟推理、代码库索引和持久化知识功能,实现高效的 AI 辅助编程。
- 💻 开源代码智能体 Cline 采用计划与执行范式,并通过智能体搜索等先进的语境工程实践,在 AI 编程领域脱颖而出。
- 🧩 字节跳动正式开源其 AI Agent 开发平台扣子 ,通过一站式可视化工具,旨在大幅降低 AI Agent 的开发与部署门槛。
- 📖 Anthropic 团队分享了他们如何玩转 Claude Code ,展示了其在代码调试、快速原型开发乃至赋能非技术人员等方面的广泛应用。
💡 产品与设计洞见
- 🌐 微软为 Edge 浏览器推出 Copilot 模式,通过跨标签页的情境感知能力,将浏览器从显示工具转变为能主动执行任务的 AI 助手。
- 🎨 一份超详细的教程,指导用户如何玩转通义万相 Wan2.2 ,内容覆盖从基础提示词公式到影视级美学控制的丰富技巧。
- 📸 火山引擎发布豆包·图像编辑模型 3.0 ,实现了通过自然语言指令进行精准 P 图,同时其 AI Agent 开发平台扣子 也正式开源。
- 🚀 一位独立开发者在四年内开发 40 多款 AI 应用,他强调了极致的快速迭代与极简的应用架构是验证 MVP 的关键。
- 🌊 大模型应用正走向深水区,阿里云副总裁安筱鹏提出了四大风向标:高价值数据 Token 化、基于强化学习的后训练、多 Agent 协同网络以及从工具到决策的跃升。
- 🎯 前 NotebookLM 团队成员分享 AI 产品心法,指出打造伟大产品的核心在于创造者自身的个人清晰度,并强调信任是氧气,克制是新的创新放大器。
📰 资讯与报告前瞻
- 💬 阿里云创始人王坚 院士在接受彭博社采访时指出,中国基础模型已足够强大,当前最大的挑战是摆脱应用思维定式,创造全新的价值场景。
- 🧠 强化学习奠基人 Rich Sutton 提出,AI 正从依赖静态数据的“数据时代”迈向通过与世界互动学习的“经验时代”,这是通向超人智能的关键路径。
- 📈 2025 年上海世界人工智能大会 WAIC 落幕,一篇总结文章指出了开源进入中国时间、芯模一体、AI Agent 成为新风口等十大核心趋势。
- 🌉 一场与 Fusion Fund 创始合伙人张璐的对谈,盘点了上半年硅谷的科技大事件,内容涵盖巨头的人才争夺、AI Agent 的崛起以及 VC 模式的转型。
- 💡 Prompt 布道师李继刚认为,AI 是一面镜子,个人记录将成为重要的数据资产,而 AI 产品的核心正从提升效率转向与用户建立信任关系。
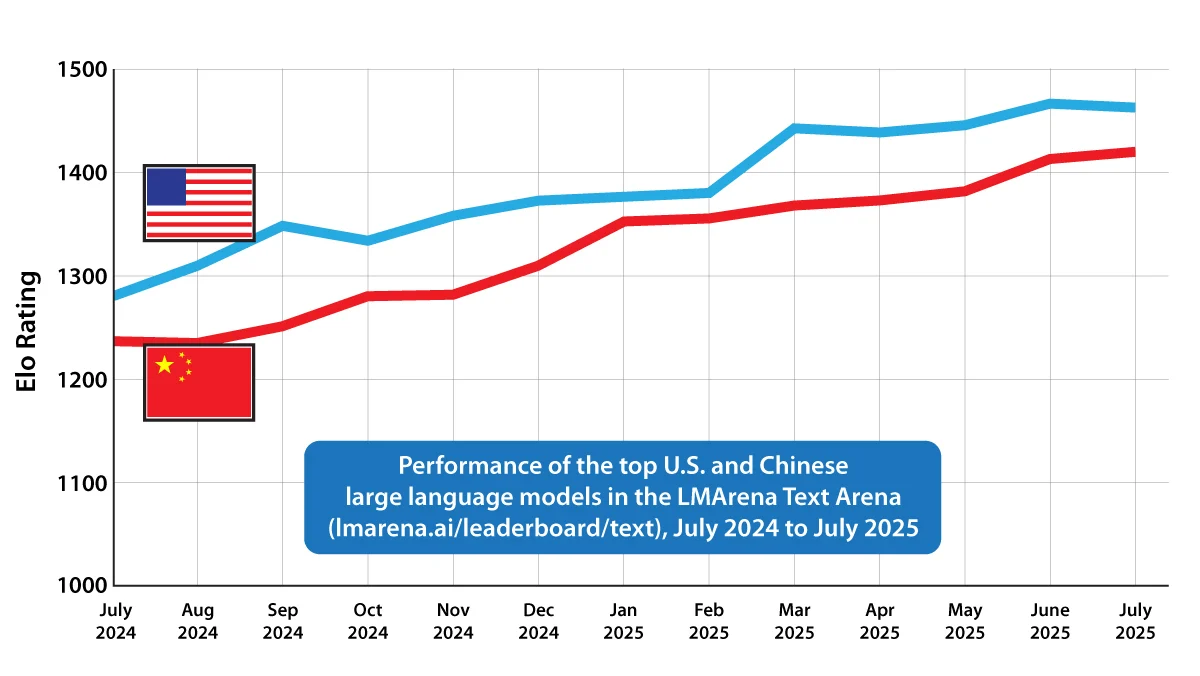
- 🇺🇸 一份新闻通讯深入分析了中美 AI 竞争的最新格局,并详细介绍了特朗普政府旨在促进开源和加强全球竞争力的新 AI 行动方案。
希望本期的精选内容能为您带来启发。我们下周再见!