大家好!欢迎查收 BestBlogs.dev 为您带来的 AI 精选文章推荐第 72 期。本周的 AI 领域异常火热,OpenAI 、百度 和月之暗面 相继发布重磅模型更新,焦点从纯粹的性能跑分转向了“情商”、全模态和智能体能力。与此同时,从 AI 领袖到一线开发者,整个行业都在深入探讨智能体的构建框架、上下文工程、乃至 AI 对就业市场的真实冲击。
🚀 模型与研究亮点:
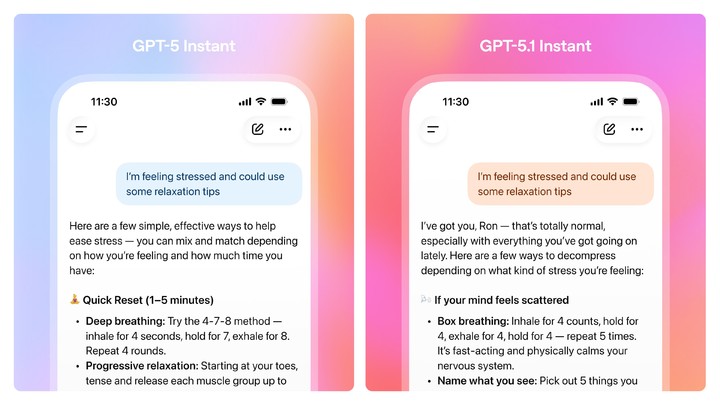
💖 GPT-5.1 正式发布,OpenAI 此次更新重点转向提升 AI 的“情商”和用户体验,而非传统跑分,并首次在安全评估中引入心理健康维度。
🎬 百度发布 2.4 万亿参数的文心 5.0 ,采用原生全模态架构,实测显示其在精确到秒级的视频内容理解和音视频融合方面表现卓越。
🗣️ 针对 Kimi K2 Thinking 的爆火争议,杨植麟团队深夜回应,否认了训练成本传闻,并直面模型输出“slop 问题”等挑战,确认了“模型即 Agent”的设计理念。
🧠 MIT 博士杨松琳深度访谈,系统剖析 Attention 机制从传统到线性、稀疏及混合架构的演进,并结合 Kimi Linear 实践探讨了算法设计与硬件亲和力的核心地位。
🔺 文章提出 2025 年是“RL 环境之年 ”,通过在模拟工作场景中测试,发现顶尖模型失败率仍超 40%,并构建了“智能体能力金字塔”框架,指出常识推理是最后屏障。
🗺️ 2025 年终开源大模型技术指南,详细对比 DeepSeekV3 、Llama4 等九大主流模型的架构演变,深入探讨 MoE 、MLA 和归一化策略等技术如何推动模型从“回答者”蜕变为“思考者”。
🛠️ 开发与工具精粹:
⚙️ 超详细总结 AutoGen 、AgentScope 、CAMEL 和 LangGraph 四大主流智能体框架的核心机制与设计理念,并分析了“涌现式协作”与“显式控制”间的关键权衡。
📦 LangChain 视频详解智能体上下文工程的三大原则:卸载 (到外部存储)、减少 (压缩和摘要) 和隔离 (使用子智能体),以解决“上下文腐烂”问题。
🎨 Claude 推出 Skills 功能,允许动态加载专业领域知识(如 React 、Tailwind CSS ),以解决 LLM 在前端设计中输出通用、缺乏个性的“分布收敛”痛点。
🤖 阿里云团队分享如何构建一个“代码驱动”的“自我编程” Agent,该 Agent 通过生成并执行 Python 代码 (而非 JSON 调用) 来实现自主决策和复杂任务处理。
🍃 Spring AI 1.1 GA 版本正式发布,带来了 MCP 协议、可降低 90% 成本的提示词缓存,以及用于构建自我改进智能体和“LLM-as-a-Judge”的创新递归顾问。
📚 HuggingFace 发布超 200 页的大模型训练“实战指南”,基于训练 SmolLM3 的经验,手把手教学从训练决策、架构设计到基础设施建设的全流程。
🧪 天猫技术团队分享从 0 到 1 构建 AI 测试用例生成系统的实践,通过“Prompt 工程 + RAG + 平台化集成 ”策略,实现 C 端业务用例采纳率超 85%。
💡 产品与设计洞见:
⌨️ Cursor CEO 在 a16z 访谈中分享其增长策略,强调专注于构建基于 VS Code 的卓越 AI 驱动 IDE,而非追求“科幻”智能体,并揭示了其“在职两天试用”的非传统招聘实践。
📈 Gamma 创始人分享其 ARR 破 1 亿美元的历程,其核心产品策略是“求异而非求同”,专注于富媒体和移动响应式内容,而非传统 16x9 幻灯片,并通过优化“最初 30 秒”体验实现病毒式增长。
📜 从 Chrome 早期网页历史功能的设计探索中吸取教训:用户总是选择“阻力最小的路径”,因此 AI 聊天历史应作为强大的幕后基础设施,而非一个需要用户主动探索的复杂功能。
📱 AI 应用 Bro 登顶 App Store,其定位不是导师,而是“损友”。它通过视觉模型实时“看到”用户在其他 App 上的操作,并以幽默、毒舌的语气进行评论。
🌐 OpenAI 播客介绍全新浏览器 ChatGPT Atlas ,它以 ChatGPT 为核心而非插件,利用“浏览器记忆”实现个性化,并采用轻量级 Swift UI 与嵌入式 Chromium 分离的架构。
📰 资讯与报告前瞻:
💰 企业销售专家 Jen Abel 分享 ARR 从 100 万到 1000 万美元的策略:从一开始就瞄准“一级客户”,并且要“销售 Alpha ”(变革性机会),而非具体功能,这一“愿景塑造”必须由创始人主导。
🐉 “杭州六小龙” (包括宇树科技 、深度求索 等) 首次同台对话,分享了在机器人、脑机接口、通用 AI 等领域的十年发展历程,并深入探讨了具身智能的数据采集等技术边界问题。
📊 洞察 100 家顶尖 AI 初创公司后发现 7 个真相:AI 企业正以更精简的团队实现高产出 (人均营收效率远超 SaaS),PLG 成为主导模式,且市场正呈现多赢局面。
💡 播客深入探讨黄仁勋的 20 条管理哲学,包括他“教授式”的领导风格、促进高效决策的扁平化组织、将痛苦视为“超能力”以及“使命即老板”的核心理念。
🌍 李飞飞最新长文指出 AI 的下一个十年最需要的是“空间智能 ”,它先于语言存在,是实现真正智能的基石。她倡导构建具备生成性、多模态和交互性的“世界模型 ”。
📉 报告分析 1.8 亿个岗位后发现,AI 正在“堵住”应届生的路。企业更倾向于“经验丰富者 + AI ”的组合,导致入门级创意执行岗位大幅减少,可能造成未来的人才断层。
感谢您的阅读,期待这些精选内容能为您带来新的启发!