
OpenAI 在 2024 年 9 月 13 日发布的 o1 大模型,通过强化学习训练显著提升了复杂推理能力。在物理、化学、生物学、数学和编程等多个基准任务上取得突破,o1 模型在国际数学奥林匹克资格考试中正确解答了 83% 的问题,远超 GPT-4o 的 13%。此外,o1 在编程竞赛中的表现也优于 GPT-4o,甚至在某些基准测试中超越了人类专家。OpenAI 还推出了成本更低、速度更快的 o1-mini 版本,特别擅长编程。文章详细介绍了 o1 的工作原理、评估结果及未来发展方向。
👋 亲爱的读者朋友们,欢迎阅读本期 BestBlogs.dev 的精选文章推送!
🚀 本周,AI 领域继续保持蓬勃发展,从模型性能的突破到实际应用的创新,我们见证了 AI 技术在多个领域的重要进展。让我们一起来了解这些精彩的发展!
💫 本周亮点
🧠 AI 模型进展:性能提升,多模态融合
⚡ AI 开发创新:效率提升,工具进化
💡 AI 应用落地:用户体验提升,商业模式探索
🌐 AI 行业动态:技术趋势,未来展望
想深入了解这些精彩的 AI 发展?点击阅读原文,探索更多内容!
OpenAI 在 2024 年 9 月 13 日发布的 o1 大模型,通过强化学习训练显著提升了复杂推理能力。在物理、化学、生物学、数学和编程等多个基准任务上取得突破,o1 模型在国际数学奥林匹克资格考试中正确解答了 83% 的问题,远超 GPT-4o 的 13%。此外,o1 在编程竞赛中的表现也优于 GPT-4o,甚至在某些基准测试中超越了人类专家。OpenAI 还推出了成本更低、速度更快的 o1-mini 版本,特别擅长编程。文章详细介绍了 o1 的工作原理、评估结果及未来发展方向。

2023 年 9 月 19 日,阿里云在云栖大会上宣布了其新一代开源大模型 Qwen2.5 的发布,这一消息在人工智能领域引起了广泛关注。Qwen2.5 系列模型不仅在性能上超越了 Llama 3.1-405B,还推出了 Qwen-Max 模型,其性能已经逼近 GPT-4o。Qwen2.5 系列涵盖了多个尺寸的大语言模型、多模态模型、数学模型和代码模型,总计上架了 100 多个模型,刷新了业界纪录。这些模型在语言处理、代码生成、数学推理和多模态处理等方面表现出色,尤其是在中文社区中引发了广泛关注。Qwen2.5 系列模型在 18 万亿 tokens 的数据上进行了预训练,整体性能相比 Qwen2 提升了 18% 以上。Qwen-Max 模型在多个权威基准测试中表现接近 GPT-4o,尤其在数学和代码能力上甚至超越了 GPT-4o。此次发布标志着中国在开源大模型领域的重大突破,为开发者提供了强大的工具和平台。
DeepSeek 公司近日发布了 DeepSeek-V2.5,这是一个融合了 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2 两个模型的新版本。DeepSeek-V2.5 不仅继承了原有模型的通用对话能力和代码处理能力,还通过优化对齐人类偏好,显著提升了写作任务和指令跟随的表现。该模型在多个测试集上表现优异,特别是在中文和英文测试中,均优于之前的版本。此外,DeepSeek-V2.5 在安全性和代码生成方面也进行了重要改进,减少了安全策略对正常问题的影响,并在代码补全任务上提升了 5.1% 的评分。该模型现已全面上线,并通过 API 向前兼容,用户可以通过 deepseek-coder 或 deepseek-chat 访问新模型。DeepSeek-V2.5 的开源版本也已发布到 HuggingFace,进一步推动了 AI 技术的开放和共享。
OpenAI 在 9 月 12 日发布了备受瞩目的新模型 o1,该模型在数学和编程问题上的解决能力显著提升,尤其是在博士级别科学题目上的成功率超过了人类专家水平。文章详细介绍了 o1 模型在推理能力上的突破,主要得益于思维链(CoT)技术和强化学习的应用。思维链技术通过引导大模型分步思维,显著提高了推理任务的正确率;而强化学习则让模型通过自学推理,进一步增强了其解决复杂问题的能力。然而,文章也指出了 o1 模型面临的挑战,包括技术壁垒不高、高昂的计算成本以及方法论上的争议。尽管 o1 在某些领域展示了超人的能力,但其商业化前景和实际应用价值仍存在不确定性。此外,文章还探讨了 o1 模型可能带来的新思路,即人工智能未来可能从单一的大模型演变为多种能力模块的灵活组合,与人类形成更紧密的协作。
文章由新浪微博机器学习团队 AI Lab 负责人张俊林详细解释了 OpenAI 新模型 o1 的技术进步及其对行业的影响。o1 模型通过自动化复杂 Prompt 和增强逻辑推理能力,显著提升了大模型的解题步骤掌握能力。张俊林认为,o1 的本质是让大模型学会了解题步骤,掌握逻辑和思维,以此增强复杂问题的解决能力。他指出,o1 这种通过 Self Play 增强逻辑推理能力的方向,未来还有很大的发展潜力。OpenAI 的 o1 模型可能会成为行业的新方向,预计很多大模型厂商会跟随这一方向发展。此外,文章还讨论了预训练 Scaling Law 的来源和 o1 提到的 RL Scaling law,强调了逻辑推理能力在大模型中的重要性。
本文探讨了 OpenAI o1 模型发布对 AGI 发展的深远影响,特别是强化学习(RL)和 Self-play RL 作为新的 scaling law 的重要性。文章指出,当前模型 scaling 面临参数、数据和算力的瓶颈,而强化学习通过 self-play 方法提升模型的逻辑推理能力,成为突破这些瓶颈的关键。文章详细讨论了强化学习在 AGI 发展中的三条主要路线:多模态、10 万卡集群和强化学习,并强调强化学习是最有可能走向 AGI 的范式级别路线。此外,文章分析了强化学习在不同领域的应用前景和挑战,以及新范式下对 GPU 需求的变化,并展望了 AI 编程工具和视频生成领域的发展趋势。
本文深入探讨了 OpenAI o1 模型在强化学习中的新范式,特别是在后训练阶段通过强化学习提升模型推理能力的重要性。文章首先介绍了 OpenAI o1 通过后训练扩展律在数学、代码和长程规划等问题上的显著进步,强调了强化学习在模型训练中的关键作用。随后,文章详细介绍了 STaR 和 Quiet-STaR 方法,通过迭代和内部思维优化模型的推理能力,减少对外部示例的依赖。此外,文章还探讨了 OpenAI o1 模型在强化学习中的技术路径,特别是通过引入隐式思维链和动态 Reasoning Token 来优化推理过程,以及如何通过 Critic Model 提供细粒度的反馈,以提升模型在复杂任务中的表现。最后,文章讨论了 AI 安全的推理链的重要性,以及 AI 控制范式在确保 AI 安全中的作用,并列出了多个与 AI 对齐和强化学习相关的学术论文链接,展示了 AI 领域在强化学习新范式下的研究进展和多样性。
豆包大模型团队在 2024 火山引擎 AI 创新巡展上海站展示了其最新的语音识别技术成果 Seed-ASR。该技术基于大语言模型,具有高精度识别、支持多种语言和方言、上下文感知等特点。通过分阶段训练方法,包括自监督学习、监督微调、上下文微调和强化学习,Seed-ASR 显著提升了语音识别的准确性和泛化能力。此外,Seed-ASR 已在豆包 APP 和火山引擎的相关服务中得到应用,并在公开及内部测评集中显示出优于其他模型的性能。

本文宣布了加速 1.0.0 的发布候选版本,这是 Hugging Face 旨在简化并增强大规模模型训练和推理的重大更新。最初作为多 GPU 和 TPU 训练的简单框架,加速已发展成为一个多方面的库,解决了大规模训练中的常见挑战。关键功能包括灵活的低级训练 API、易于使用的命令行界面以及对大型模型推理的支持。发布候选版本引入了几个新的集成和改进,如 FP8 支持、DeepSpeed 编排和 torch.compile 支持。此外,它强调了该包在提高训练效率和简化用户操作方面的作用。未来的路线图包括进一步集成新兴的 PyTorch 生态系统技术,如 torchao (一个用于优化 PyTorch 训练的工具) 和 torchtitan (一个用于大模型训练的工具),旨在为 FP8 训练和分布式分片提供强大的支持。本文还为过渡到新版本的用户提供了迁移帮助,详细说明了弃用和变更。
本文深入探讨了微调(Fine-tuning)大语言模型的各个方面,从基本概念到具体技术实现,再到实际应用和未来趋势。文章首先介绍了微调的基本概念,强调了其在特定任务上的能力增强、性能提升、数据安全及成本降低等方面的优势。接着,详细介绍了微调的具体技术,包括监督微调(SFT)、强化学习(RLHF)和 LoRA 等高效微调技术。特别地,LoRA 通过引入低秩矩阵显著减少了微调过程中需要更新的参数数量,从而降低了计算资源需求,并具有高度的可重用性。文章还详细描述了使用 LoRA 技术微调大语言模型的过程,包括数据量要求、代码实现和效果评估,展示了微调对模型性能提升的重要性。此外,文章还介绍了如何使用 Python 和 Hugging Face 的 Transformers 库进行微调,包括数据集的创建、模型的加载、标签映射的定义以及 tokenizer 的使用。最后,文章讨论了微调的成本问题和未来趋势,强调了数据质量的重要性,并提供了相关参考链接。
本文由大淘宝技术团队撰写,详细介绍了大模型训练的全过程,包括数据处理、模型预训练、微调策略选择、显存资源优化以及模型评测方法。文章强调了数据隐私保护和数据质量的重要性,并讨论了如何通过调整关键参数和选择合适的微调方案来优化训练效果。此外,还介绍了 LoRA 训练方法和四种主要的微调模式,以及如何通过评测确保模型性能的全面性。最后,文章提到了淘天集团「终端平台-研发平台」团队在移动端 DevOps 平台建设方面的努力,展示了技术团队在提升研发效能和改善工程师体验方面的成果。
本文详细介绍了 LangChain 框架,这是一个结合大型语言模型与其他知识库和计算逻辑的强大工具,旨在增强 AI 应用的功能。文章首先概述了 LangChain 的核心概念,包括模型、提示词、示例选择器和输出解析器,并通过具体案例展示了如何使用这些工具。接着,文章深入探讨了如何使用 LangChain 处理和索引文档数据,以及如何构建完整的 AI 应用,包括文档加载、文本分块、嵌入向量计算、向量库创建和检索问答系统。此外,文章还介绍了 LangChain 中的 Agent 类型及其执行流程,以及如何使用 LangChain 实现多种 AI 功能,如生成诗词、提示词转换和图片生成。LangChain 在推动 AI 技术发展和应用方面具有巨大潜力,尤其是在增强开源模型能力方面。
文章深入探讨了 Llama 3 的发布和部署策略,这是 Meta 对其开源大型语言模型(LLM)的最新迭代。Llama 3 提供了 8B 和 70B 参数版本,并计划在未来推出 400+B 版本。文章强调了在 AWS 上部署的便捷性,无论是通过 GPU 支持的 EC2 实例、SageMaker Jumpstart,还是通过 Amazon Bedrock 的专有 API。它还突出了 Llama 3 在微调方面的民主化,显著降低了企业部署基于 LLM 应用的门槛。文章将 Llama 3 与其前身 Llama 2 进行了比较,指出架构差异不大,但在数据工程方面有显著改进,这归功于模型性能的提升。Llama 3 的训练涉及超过 15T 个标记,是 Llama 2 所用数量的七倍,并包括广泛的数据过滤和质量保证过程。部署选项详细探讨了在本地机器、AWS EC2 实例以及 SageMaker Jumpstart 和 Amazon Bedrock 等托管服务上运行 Llama 3。文章提供了在 AWS 上部署 Llama 3 的逐步说明,包括设置 EC2 实例、配置环境以及运行推理脚本。它还介绍了 vLLM 以实现高效的 LLM 推理和部署。文章最后讨论了 Llama 3 变体在 HuggingFace 上的快速扩散,展示了扩展的上下文窗口和其他专业应用,强调了模型的多功能性和在各种实际应用中的潜力。
文章深入探讨了提示工程的关键原则和未来发展趋势。首先,文章强调了提示工程的核心在于清晰的沟通和理解模型的心理,类似于与人交谈。提示工程不仅仅是写作,还需要工程思维和实验能力,通过试错和迭代不断优化提示。其次,文章讨论了在开发和使用语言模型时,如何有效地进行提示和沟通,强调了不需要角色扮演,应实话实说,并尽量具体地描述当前场景。此外,文章还提到了通过挑战模型能力的极限来提高提示词编写技巧的重要性,以及在提示设计中应避免过度依赖预训练模型的模式。最后,文章展望了提示工程的未来发展趋势,指出模型将更擅长理解用户意图,并可能主动从用户那里提取信息,而不是依赖用户提供所有信息。

蚂蚁集团在 2024 Inclusion・外滩大会上发布了其最新的研发成果——知识增强大模型服务框架 KAG。该框架通过结合知识图谱与大语言模型,旨在提升垂直领域决策的精准性和逻辑严谨性。KAG 框架的核心在于通过图谱逻辑符号引导决策和检索,补全知识图谱的稀疏性和知识覆盖的不足,同时利用大语言模型的理解和生成能力降低领域知识图谱的构造门槛。在实际应用中,KAG 框架已在支付宝的 AI 原生 App "支小宝" 中得到验证,显著提升了政务问答和医疗问答场景的准确率。文章详细介绍了 KAG 框架的五个增强方面:知识表示的增强、图结构与文本互索引、符号引导的拆解和推理、基于概念的知识对齐、KAG Model。这些增强措施旨在解决大语言模型在垂直领域应用中的挑战,如复杂决策能力不足、事实性不足和幻觉问题。通过这些增强措施,KAG 框架在垂直领域的适用性得到了有效验证,并在实际业务中取得了显著的精度提升。此外,文章还提到 KAG 框架将进一步向社区开放,并在开源框架 OpenSPG 中原生支持,欢迎社区共建。这表明蚂蚁集团不仅在技术研发上取得了突破,还积极推动技术开源和社区合作,以促进整个行业的发展。

GitHub 博客宣布了 OpenAI 的 o1-preview 和 o1-mini 模型在 Azure 上托管的预览版,这些新型人工智能模型配备了高级推理能力,允许它们使用内部思维过程来思考复杂任务。在预览期间,开发者可以在 Visual Studio Code 中的 GitHub Copilot Chat 和 GitHub 模型测试环境中测试这些模型。o1-preview 模型展示了卓越的推理能力,能够更深入地理解代码约束和边缘情况,从而提供更高效和更高质量的代码解决方案。开发者可以在对话中切换 o1-preview 和 o1-mini 模型,从快速解释 API 或生成样板代码切换到设计复杂算法或分析逻辑错误。预览旨在为开发者提供模型解决复杂编码挑战和集成到他们自己的应用程序中的第一手体验。这些模型还提供了优化代码和提高开发效率的潜力,尽管开发者应考虑集成挑战。
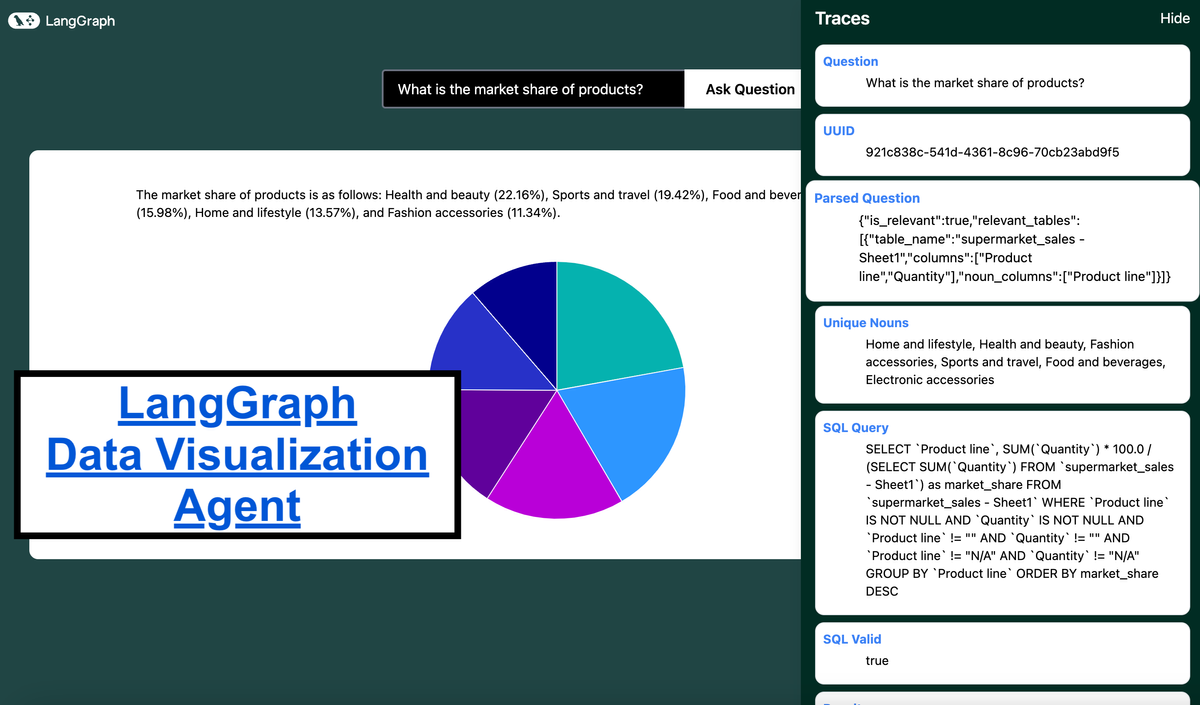
本文由 Dhruv Ateja 撰写,发表在 LangChain 博客上,提供了一个使用 LangGraph 云构建数据可视化代理的综合指南。该代理旨在处理查询数据和根据用户输入选择适当的可视化。该项目利用了 LangGraph 云的流式 API,便于实时更新和监控代理的行为。文章概述了整个工作流程,从模式和元数据提取开始,经过嵌入创建、实体和上下文检索、使用检索增强生成 (RAG,Retrieval-Augmented Generation) 提取相关表、处理大型模式、表和相关性验证、SQL 查询生成,最后是查询结构验证。实施重点放在较小的数据集上,简化了过程,无需使用 RAG 或局部敏感哈希 (LSH,Locality Sensitive Hashing) 技术。文章还提供了一个详细的 Python 代码片段,用于设置图工作流程,包括节点定义和边连接。此外,它还涵盖了模式提取、解析用户问题、生成 SQL 查询、验证和修复 SQL 查询、执行 SQL 查询以及选择适当的可视化。文章最后讨论了适合不同类型数据分析问题的可视化类型。

本文由复旦大学 CodeWisdom 团队联合南洋理工大学和 UIUC 共同撰写,对 106 篇相关文献进行了梳理和解读,全面展示了 AI 智能体在软件工程领域的最新进展。文章从软件工程和 Agent 两个视角出发,详细介绍了 Agent 在软件开发全周期各个任务上的应用现状,包括端到端的软件开发和维护任务,以及特定的软件开发和维护环节。此外,文章还探讨了 Agent 的基础架构、多智能体设计模式以及人机协同模式。最后,文章展望了 Agent 在软件工程领域的研究机会与发展方向,包括更全面的评测基准、探索人机协同新范式、多模态感知、将 Agent 应用于更多软工任务、训练面向软件工程的基座大模型以及将软件工程领域知识融入 Agent 设计。
本文介绍了 OpenAI 的全新 o1-preview 模型,该模型已与 GitHub Copilot 集成,以增强其解决复杂编码问题的能力。模型的高级推理能力使其能够将复杂任务分解为结构化步骤,使其在优化复杂算法和修复性能错误方面特别有效。文章重点介绍了两个具体场景:一个场景是模型优化了 Copilot 分词器库中使用的字节对编码器,另一个场景是它快速识别并解决了 GitHub 文件视图代码中的性能错误。文章还提到了 o1-preview 和 o1-mini 模型在 GitHub 市场中的可用性,早期访问需要注册 Azure AI。开发者的反馈表明,生产力和满意度显著提高,强调了模型高级推理能力的实际效益。将 o1-preview 集成到 GitHub Copilot 中被视为利用 AI 推动开发者生产力和提高开发者满意度的重大步骤。
本文详细解读了百度在大模型原生安全构建方面的探索和实践。文章指出大模型在内容安全方面面临的挑战,特别是在多模态输入和多轮会话中,传统内容审核技术难以应对。百度通过数据清洗、内生安全与安全对齐、安全围栏建设等方法,确保大模型在训练、部署和运营阶段的安全。数据清洗是构建安全体系的基础,安全围栏通过快速响应机制补齐安全漏洞;持续评估和迭代是确保大模型安全性的关键。此外,百度还采用了有监督精调、人类反馈强化学习、安全内容萃取等方法提升模型安全性。通过结构化查询和避免多轮会话等原则,形成纵深的防御体系。

阿里云在云栖大会上发布了「通义灵码」的全新升级,推出了 AI 程序员功能。这一功能能够自主完成从需求分析、代码编写、缺陷修复到测试的全流程开发任务,显著提升了开发效率。即使是没有编程经验的用户,也能通过简单的提示词快速生成代码,降低了编程的门槛。AI 程序员支持集成阿里云的 DevOps 平台云效和 GitHub,使得开发过程更加便捷。通义灵码基于通义大模型,具备强大的语义理解和代码生成能力,显示了 AI 在编程领域的广泛应用前景。

文章首先介绍了当前搜索引擎市场的现状,指出传统搜索引擎和推荐引擎在过去几十年中主导了信息经济的发展。随着大语言模型(LLM)的出现,AI 搜索有望成为新的主导力量。文章详细分析了 AI 搜索的三种主要流派:保守派、中间派和原生派。保守派在现有搜索引擎上添加 AI 功能模块,中间派通过 AI 对搜索进行深入改造但保留传统搜索引擎的基础设施,而原生派则从零开始打造 AI 原生的搜索引擎。原生派搜索引擎在回答质量、信息结构化和知识引用方面表现出显著优势。文章进一步探讨了打造 AI 原生搜索引擎的技术门槛和成本,包括智能索引库、专属知识库和混合大模型智能调度系统三大支柱。最后,文章讨论了 AI 搜索的商业可行性和未来发展趋势,指出尽管 AI 搜索的推理成本较高,但随着技术进步和市场竞争,成本有望下降,AI 搜索将成为未来搜索引擎的主导力量。
本文深入探讨了三款笔记应用——flomo、闪念贝壳和 Me.bot——在 AI 时代的不同产品哲学和应用策略。flomo 强调“AI 辅助,人类主导”,主张用户通过写笔记锻炼自己的“第一大脑”,而非依赖 AI 生成内容。闪念贝壳则通过 AI 技术帮助用户快速记录和整理想法,降低输入成本,目标是成为用户的“第二大脑”。Me.bot 通过 AI 技术帮助用户串联记忆,提供个性化反馈,追求与用户思维的深度融合。文章详细对比了三款应用在 AI 整合和用户互动方面的策略,探讨了它们如何平衡用户主动思考与 AI 辅助之间的关系,并反映了各自的产品哲学。总体而言,本文强调了 AI 在笔记应用中的潜力和未来发展方向,同时突出了用户自主思考的重要性。
本文介绍了 GenSpark 推出的新产品 Autopilot,该产品通过多轮反思和交叉验证,旨在提升搜索结果的深度和全面性。文章通过五个问题详细解析了 Autopilot 的工作原理和实际效果。首先,Autopilot 通过多轮反思和交叉检查,确保搜索结果的准确性和全面性。其次,反思轮数是动态的,根据反思质量可能是 0 轮、1 轮或多轮,以达到最佳效果。第三,多轮反思确实能提升答案质量,尤其在复杂问题上效果更为明显。第四,交叉检查虽然消耗更多 Token,但能显著提高答案准确性,对于重要决策很有价值。最后,Autopilot 的理念与 OpenAI 的新模型 o1 类似,都是用更多算力和时间换取更高质量的答案。文章还通过具体案例展示了 Autopilot 在实际应用中的效果,并探讨了其在不同场景下的潜在价值。
本文详细介绍了 Clari 的收入管理平台及其在销售领域的应用,探讨了销售过程中的关键要素和策略。文章首先介绍了 Clari 平台如何通过 AI 技术为 1500 多家客户管理 4 万亿美元的收入,强调了深入研究客户业务、理解客户约束条件的重要性。随后,文章讨论了优化营收的 4C 法则(创造、转化、成交、流失),并提出了在当前宏观经济环境下,销售策略应注重长期成功。此外,文章还强调了销售过程中的真诚沟通、精细化管理以及团队合作的重要性。最后,文章探讨了垂直市场销售策略的优势和招聘优秀销售人员的关键特质。
微软在 Copilot 第二弹发布会上宣布了 Office 全家桶的重大升级,旨在通过 AI 技术彻底改变全球十亿打工人的办公方式。主要亮点包括 Copilot Pages,一个集成上网搜索、内容策划和团队写作的 AI 工具;AI 生成 Python 代码的 Excel 集成,用户可以直接在 Excel 中编写和运行 Python 代码;以及一键生成 PPT 的 Narrative Builder。这些功能得到了 o1 模型的加持,推理性能更高,响应更快。微软表示,这些新功能将免费向所有用户开放,以大幅提升生产力。
在 2024 云栖大会上,杨植麟、姜大昕、朱军等专家围绕大模型技术路径展开深入讨论。文章回顾了 AI 技术在过去 18 个月内的快速发展,特别是在大模型、多模态融合和自动驾驶等领域的突破。分析了 OpenAI 的新模型 o1 带来的技术突破和范式变革,通过强化学习提升 AI 的推理和泛化能力。探讨了大模型技术路径中的关键问题,如算力扩展、数据墙、训练与推理算力的变化,以及新范式对算力和数据需求的影响。讨论了产品形态的变化、推理能力向物理世界的落地,以及创业公司在 AI 领域的创新空间和算力需求。最后,文章展望了基础模型与应用创新、AI 应用的增量价值、AGI 领域的进展,尤其是未来 18 个月内 L3 和 L4 可能取得的显著进展。
杨植麟在最新分享中详细讨论了大模型发展的下一个重要范式——强化学习,并分析了通用模型产生的三个关键因素:互联网数据、计算能力和算法提升。他强调了通用智能对社会 GDP 的潜在杠杆效应,并探讨了 AGI 面临的三个层面挑战:规模化定律、多模态统一表示和长上下文推理。此外,杨植麟还预测了 AI 技术的发展趋势,强调文本模型能力的重要性以及多模态模型的发展前景,并认为 AI 将在未来 5 到 10 年内实现大规模市场应用。他还讨论了 AI 模型的潜力及其在生产力提升中的作用,强调了数据作为变量的重要性,以及 AI 与人类价值观对齐的必要性。
本文通过谷歌 AI 负责人 Jeff Dean 的访谈,深入探讨了谷歌在人工智能领域的最新进展与挑战,尤其是 Gemini 大模型的开发及其在教育和医疗等领域的应用。Jeff Dean 分享了在推动 TensorFlow 和 Google Brain Team 发展中的关键角色,这些努力使得大规模神经网络训练成为现实。文章详细介绍了 Gemini 多模态模型的潜力,如何通过处理文本、图像、音频和视频带来跨领域的革命性变化。Jeff Dean 强调了 Transformer 架构在并行处理和高维空间表示法方面的优势,同时也指出了通过技术改进和公众教育应对 AI 偏见和事实性问题的必要性。文章还探讨了个性化模型和链式思维提示技术在多模态模型中的应用。
在 2024 云栖大会上,阿里巴巴集团 CEO 吴泳铭发表了关于 AI 未来发展的主题演讲。他指出,过去 22 个月 AI 的发展速度前所未有,但仍处于 AGI 变革的早期阶段。大模型技术的快速迭代使得技术可用性大幅提升,模型推理成本显著下降,开源生态蓬勃发展。吴泳铭强调,AI 的最大潜力不在于手机屏幕上的应用,而是通过接管数字世界并改变物理世界,带来革命性的生产力提升。他预测,未来几乎所有软硬件都将具备推理能力,计算体系将由 GPU 主导。此外,AI 将推动汽车和机器人行业的巨变,提升物理世界的运行效率。阿里云正在大力投资 AI 技术研发和基础设施建设,以应对日益增长的 AI 算力需求。
本文是 Limitless AI 创始人 Dan Siroker 的详细访谈,涵盖了从连续创业者与首次创业者的区别到融资谈判的秘诀,再到如何识别和投资有潜力的 AI 项目。Siroker 强调了执行力的重要性,指出连续创业者之所以成功,是因为他们能够聚焦于真正决定公司成败的少数关键事务。此外,他还分享了在融资谈判中理解投资者动机的重要性,以及如何通过产品主导的增长策略吸引大型企业客户。文章还涉及了创业公司在人力资源管理、薪酬策略和股票交易方面的策略,以及如何在融资过程中有效管理投资者关系和期望。

文章首先回顾了近年来人工智能模型能力的显著提升,特别是计算资源的增长对性能提升的贡献。文章指出,人工智能训练计算的增长速度甚至超过了历史上一些最快的技术扩张,如移动电话采用率和太阳能装机容量。随后,文章引用了 Epoch AI 的报告,探讨了当前人工智能训练规模的快速增长(约每年 4 倍)在 2030 年之前是否始终在技术上可行。报告提到了可能制约扩展的四个关键因素:电源可用性、芯片制造能力、数据稀缺性和“延迟墙”。文章详细分析了每个因素的现状和未来发展潜力。电力方面,文章讨论了数据中心电力容量的快速扩张潜力,并引用了多种资料来源和预测来支持这一观点。芯片制造能力方面,文章提到了先进封装和高带宽内存生产能力的限制,并预测了未来芯片制造能力的扩展。数据短缺方面,文章讨论了多模态数据和合成数据对扩展的潜在贡献。最后,延迟墙方面,文章探讨了并行处理和网络拓扑结构对克服延迟限制的影响。文章还讨论了这些限制因素对人工智能扩展的综合影响,并预测到 2030 年可能训练出规模超过 GPT-4 的模型。文章最后探讨了人工智能实验室是否真的会追求这种水平的扩展,以及这种扩展可能带来的经济影响。