大家好!欢迎阅读 BestBlogs.dev 为您带来的第 49 期 AI 精选文章推荐。本周 AI 领域热点频出,各大厂商与研究机构在模型能力提升、开源共享、以及 AI Agent 的探索上持续发力,开发者生态工具链日趋完善,AI 原生产品的创新与商业化实践也亮点纷呈。让我们一同快速浏览本周的精华内容!
🚀 模型与研究亮点:
- 🌟 DeepSeek-R1 发布小版本更新 DeepSeek-R1-0528 ,基于 DeepSeek V3 Base 基座增强后训练,显著提升了模型的思维深度与推理能力,幻觉率大幅降低约 45-50%,并开源了蒸馏其思维链到 Qwen3-8B 上的模型。
- 🖼️ 字节跳动开源其多模态模型 BAGEL (或称 SD3-Turbo-Chat ),号称具备 GPT-4o 级别的图像生成与理解能力,采用 MoT 架构集成了带图推理、图像编辑、3D 生成等多种功能于一体。
- 📚 阿里巴巴通义实验室开源长文本深度思考模型 QwenLong-L1 ,通过创新的渐进式强化学习训练框架,有效解决了现有大模型在处理长文本时推理效率低和训练不稳定的痛点。
- ✍️ 通义实验室同时开源了针对可达 2M Token 超长上下文的 QwenLong-CPRS ,提出动态上下文优化范式,允许通过自然语言指令进行多粒度信息压缩,显著提升超长基准性能。
- 🎨 Black Forest Labs 推出的 FLUX.1 Kontext 模型在文本驱动图像编辑方面展现卓越性能,支持准确的图像修改、风格迁移及图像内文本编辑,并保持角色一致性。
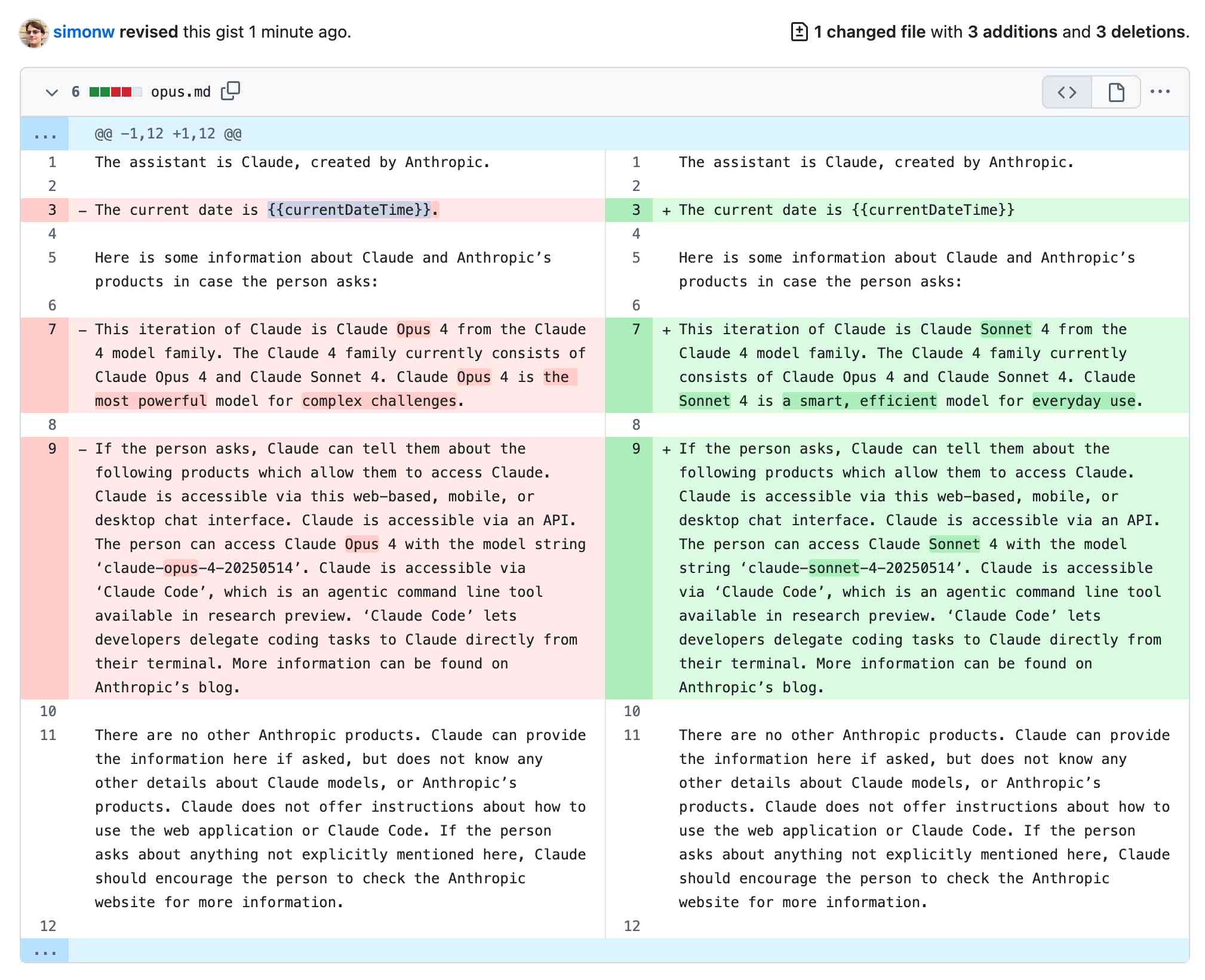
- 🔍 对 Anthropic Claude 4 (Opus 和 Sonnet)模型系统提示的深入剖析揭示了其塑造模型行为、个性、安全防护以及处理工具调用和“红旗”指令的详细内部机制。
🛠️ 开发与工具精粹:
- 📊 Jina AI 推出 jina-reranker-m0 模型,并提出有效的两阶段检索流程,以解决多模态文档(含文本和图像)因模态鸿沟导致的排序不准确问题,显著提升检索召回率。
- ✍️ 来自 Augment Code 的实践分享了构建高性能 AI 智能体的 11 种关键提示工程技巧,强调提供高质量上下文、构建完整“世界观”以及像管理代码一样管理 Prompt 的重要性。
- 🏗️ InfoQ 总结了超越传统 GoF 的现代 AI 系统实用设计模式,将其分为提示与上下文模式、负责任的 AI 模式、用户体验模式、AI-Ops 模式及优化模式五大类别。
- 🏆 Datawhale 详细解析了 RAG 挑战赛中构建基于公司年报的智能问答系统的冠军方案,重点介绍了 PDF 解析、LLM 重排序、父页面检索及结合 CoT 与结构化输出的提示工程。
- 🔗 文章探讨了 Anthropic 提出的 MCP (Model Context Protocol) 标准,并展示了利用 MCP 连接数据库(如 MongoDB )进行结构化数据检索的新方法,有望提升 RAG 在此类场景下的效果。
- 🗺️ InfoQ 万字长文基于 OpenDigger 和 GitHub 数据,对大模型开源开发生态进行了全景分析与趋势解读,覆盖模型训练、高效推理、应用开发、Agent 框架及向量数据库等关键领域。
💡 产品与设计洞见:
- 🤖 腾讯科技对当前热门的 AI Agent 产品 Manus 、Flowith 和 Lovart 进行了多场景实测对比,分析了它们在不同任务中的表现、优缺点、适用性及商业化潜力。
- 🌱 Anthropic 首席产品官 Mike Krieger 在深度访谈中分享其产品哲学:最好的 AI 产品如 Claude 和 MCP 协议,应从底层自发“长出来”,而非刻意规划,并探讨了 Agent 的核心要素。
- 💰 深思圈深度剖析了独立开发者 Eric Smith 如何凭借 AI 视频工具 AutoShorts AI ,在 9 个月内从 0 做到月收入近 10 万美元,揭示了其成功的核心因素与增长策略。
- 🎭 Kotoko AI 创始人乔海鑫在访谈中阐述其产品 Bside 的理念,旨在通过 AI Agent 赋予用户原创角色(OC)生命力,连接以 05 后为主的年轻群体,打造“创造-养成-社交/陪伴”的完整闭环。
- 💻 硅谷科技评论详细剖析了由奥赛金牌团队创立的 Cognition 公司及其 AI 编程代理 Devin ,探讨了其技术架构、能力边界、商业模式、高估值以及面临的市场竞争与技术挑战。
- 🎙️ AI 炼金术播客对话浮墨笔记和产品沉思录主理人少楠,探讨了在 AI 热潮下,如何像设计产品一样设计 Prompt,务实整合 AI 功能,并通过深层理念和用户体验构建产品差异化。
📰 资讯与报告前瞻:
- 🌐 微软 CEO 萨提亚·纳德拉在 Build 大会后接受访谈,指出 AI 正在引发一场范式巨变,应用层将“坍缩并融入智能体”,传统 SaaS 应用需适应成为智能体网络中的“后端”。
- 📢 “开始连接 LinkStart”播客节目聚焦 Google I/O 2025 大会,邀请多位专家深度解析 Gemini 模型、Agent 技术、AI 搜索及 AR/VR 应用,并探讨 AI 创业公司的新机遇。
- 🔄 Arc 浏览器创始人 Josh Miller 在 Founder Park 的文章中复盘了为何放弃拥有百万用户的 Arc,转而从零开始开发全新 AI 原生浏览器 Dia ,旨在抓住 AI 时代的新机遇。
- 👥 腾讯研究院访谈特赞创始人范凌博士,探讨其对 AI Agent 边界与潜力的独到见解,特别是 Agent 在模拟真实用户和主观世界、以及利用“幻觉”进行商业研究方面的潜力。
- 💡 YouWare 创始人明超平在播客“张小珺商业访谈录”中,将当前 AI Agent 的发展阶段比作“刚拿起烧火棍的大猩猩”,并分享了其对于 AI 原生产品理念以及“per token valuation”这一关键价值衡量指标的深刻洞察。
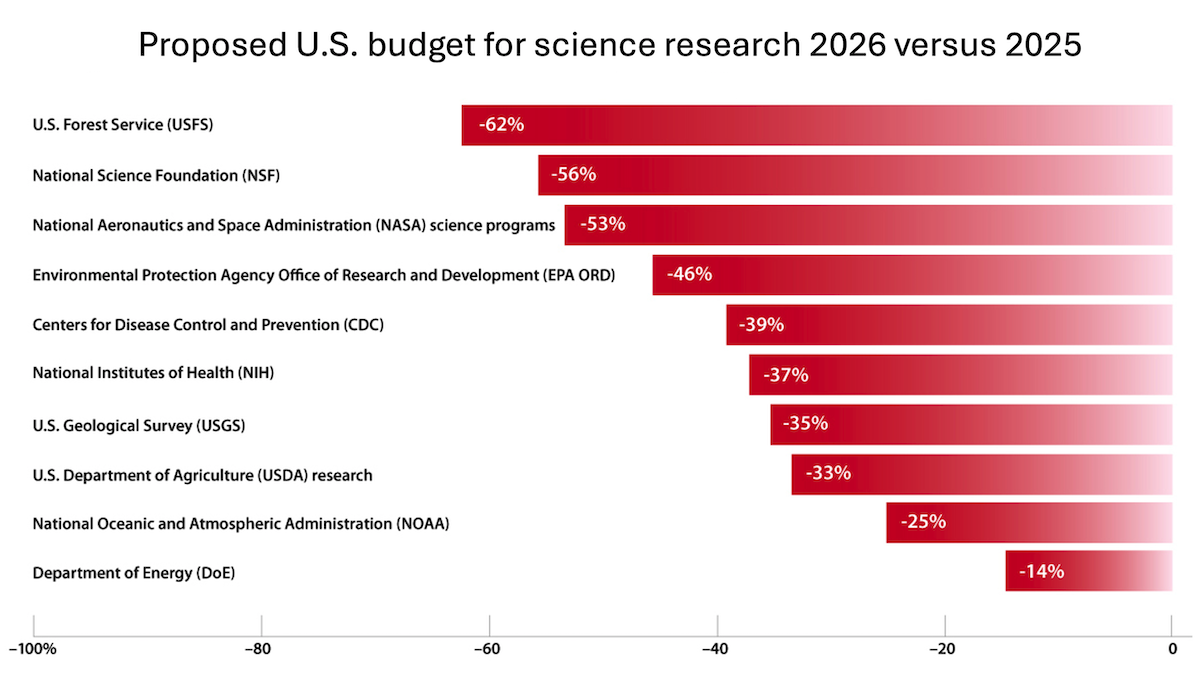
- 🌍 deeplearning.ai 的 "The Batch" 新闻通讯关注了 Anthropic Claude 4 在编码能力和智能体功能上的提升,总结了 Google I/O 开发者大会的主要 AI 公告,并提及基础科学研究资金的重要性。
以上就是本周的 AI 精选亮点,希望能为您带来启发。AI 的浪潮奔涌向前,精彩永不停歇,敬请持续关注 BestBlogs.dev,获取前沿动态!