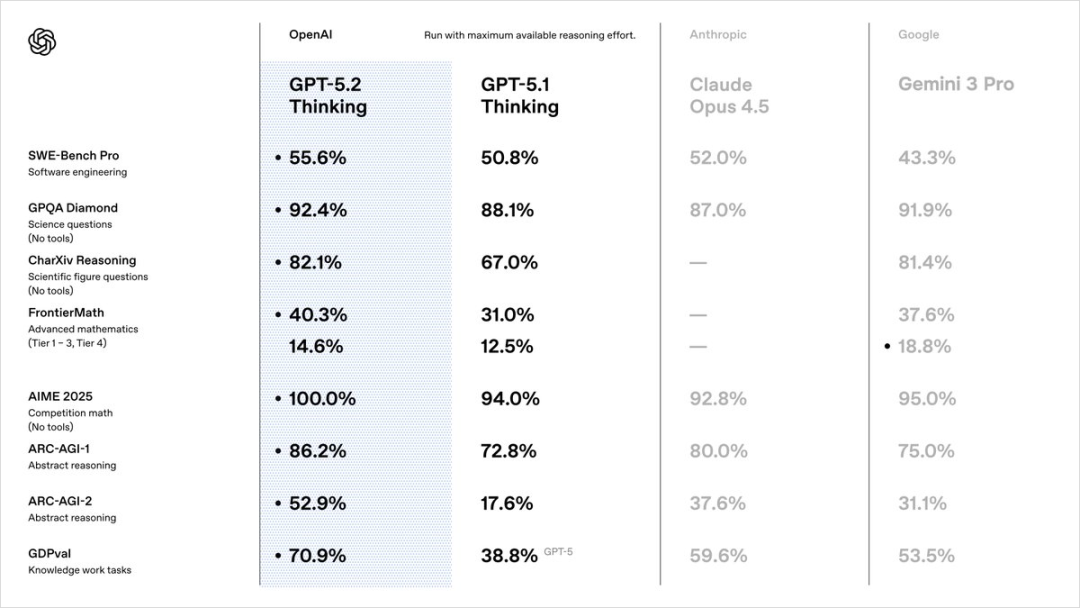
OpenAI 十周年发布 GPT-5.2,这次更新的核心是「专业知识工作」能力的跃升。文章深度解析了两个关键评测:ARC-AGI-2 测试流体智力的得分从 17.6% 飙升至 52.9%,而 GDPval 评测显示模型在 44 个真实职业任务中,有超过 70% 的表现达到或超越 14 年经验的行业专家水平。作者特别强调这是一次务实的迭代,不再只为程序员服务,而是真正面向律师、设计师、市场经理等广大白领打工人,聚焦解决实际工作场景中的复杂问题。
大家好!欢迎阅读 BestBlogs.dev 第 76 期 AI 精选文章推荐。
本周最让我印象深刻的,是 Anthropic 在 AI Engineer 大会上提出的一个观点:不再构建智能体,转而构建技能。他们认为当前智能体的核心问题在于「有智力却缺乏领域专业知识」,就像让高智商数学家去报税——能力很强,但经验不足。技能的本质是把过程性知识打包成可复用的文件夹,支持版本控制、团队共享,还能与 MCP 服务器无缝集成。巧合的是,MCP 本周正式移交 Linux Foundation 管理,8 个月内获得 37,000 star,验证了标准化的强烈需求。我在想,当「模型 + 运行时环境 + 技能库 + MCP」这套架构逐渐成型,Skills 是否有可能像 Docker 镜像一样,成为跨模型、跨产品的通用能力载体?这或许是 AI 开发从「造轮子」走向「标准化组件」的关键一步。
以下是本周最值得关注的 10 个精彩亮点:
🤖 GPT-5.2 发布,OpenAI 把这次更新定位为「牛马打工人专属 AI」。不再只为程序员服务,而是面向律师、设计师、市场经理等广大白领。在 44 个真实职业任务的评测中,超过 70% 的表现达到或超越 14 年经验的行业专家水平。务实的迭代,解决实际问题。
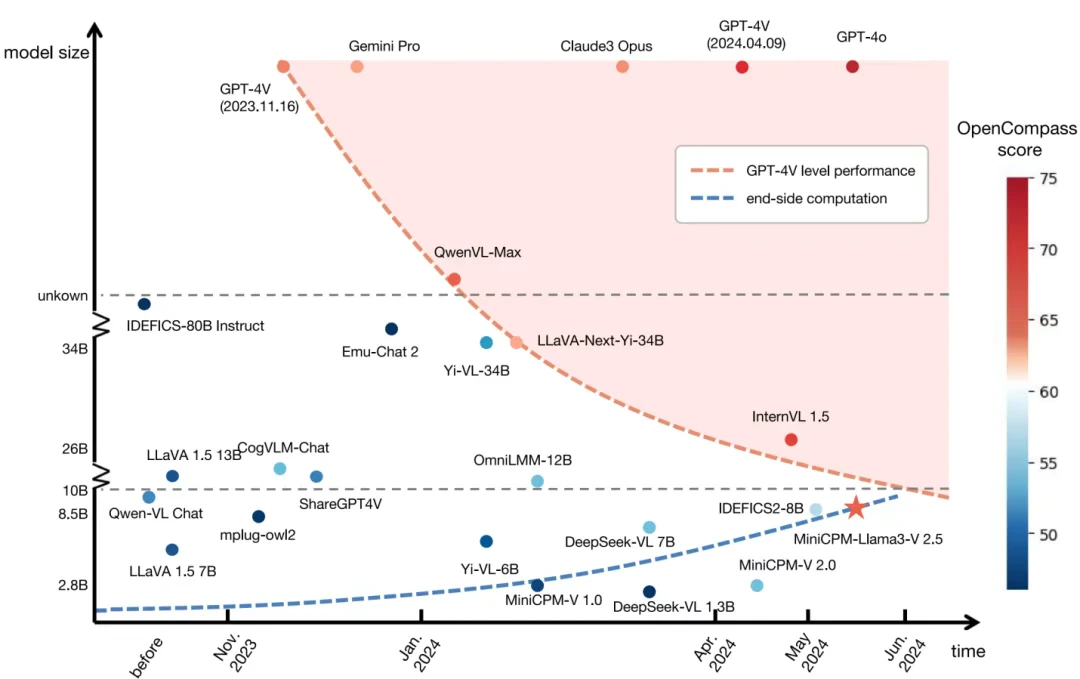
🔬 清华刘知远团队在《自然·机器智能》发表的密度法则研究揭示了 AI 领域的「摩尔定律」:模型训练和推理效率每 3.5 个月翻倍。这解释了为什么端侧模型能快速追平云端巨头,也预测了 2027 年手机上可部署具备自主学习能力的专属大模型。
📊 斯坦福基于 12 万开发者的研究发现,代码库健康度与 AI 收益呈 0.40 相关性。整洁的代码能放大 AI 效果,而技术债务会加速熵增。更关键的是,单看 PR 增长 14% 可能掩盖代码质量下降 9% 和返工增加 2.5 倍的事实——最终 ROI 可能为负。
💡 Manus 创始人张涛首次系统回应外界质疑,核心理念是「Less structure, more intelligence」。通过 Zero Predefined Workflow 将任务决策完全交还给模型,在多个 Benchmark 中长期保持领先。应用层团队凭借模型选择灵活性,也能对抗 OpenAI 等巨头。
🌐 a16z 2026 年预测指出,Agent-native 基础设施将成为必需品,核心挑战从算力转向多 Agent 协调能力。更关键的洞察是:99% 的市场机会存在于传统垂直行业,而非硅谷科技圈。企业软件的价值将从记录系统转向智能执行层。
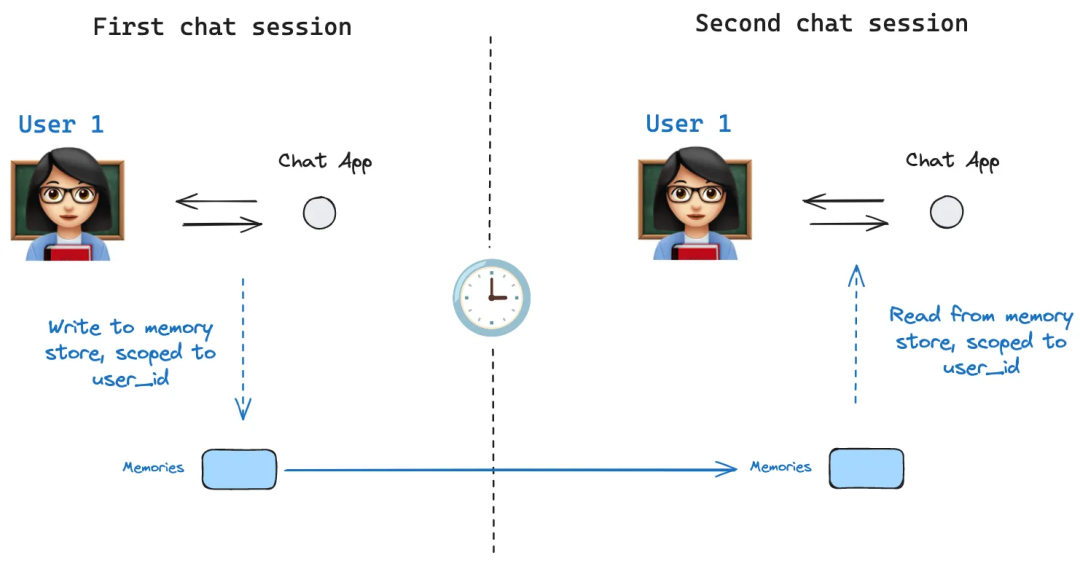
🛠️ 腾讯技术团队详细讲解了如何让 AI 智能体拥有持久记忆。基于 LangGraph 框架,短期记忆通过 Checkpointer 管理单次对话状态,长期记忆通过 Store 实现跨会话知识共享。从 InMemorySaver 到 PostgreSQL 持久化,再到语义搜索,代码示例非常完整。
🎨 智谱开源 GLM-4.6V 系列,最大创新是将 Function Call 能力原生融入视觉模型,实现「图像即参数,结果即上下文」的多模态工具调用。9B 的 Flash 版本超越 Qwen3-VL-8B,API 价格降低 50%,完全开源。
📈 Dify 创始人路宇复盘两年创业历程,揭示 GitHub 11 万+ star 项目背后的战略思考。坚持工程价值和模型中立性,从 high code 向智能化的务实转型,以及在日本市场意外获得的现象级成功。对 AI 应用「最后一公里」问题有深刻理解。
🏆 OpenRouter 和 a16z 联合发布的报告基于 100 万亿 Token 真实数据,揭示了几个关键转折:中国开源模型份额从 1.2% 暴涨至近 30%;推理优化模型流量占比超过 50%;编程占据总流量的一半以上。「水晶鞋效应」理论值得关注——模型留存的关键在于能否在发布时就完美解决特定痛点。
🧩 朱啸虎在年末对 AI 产业深度复盘,明确指出至少三年内看不到 AI 泡沫。当前竞争的核心已从模型能力转向超级入口之争。对于创业者,他建议「错开共识 15 度」,聚焦大厂不愿涉足的垂直场景和苦活脏活。
希望本期的推荐能为您带来新的启发。保持好奇,我们下周见!