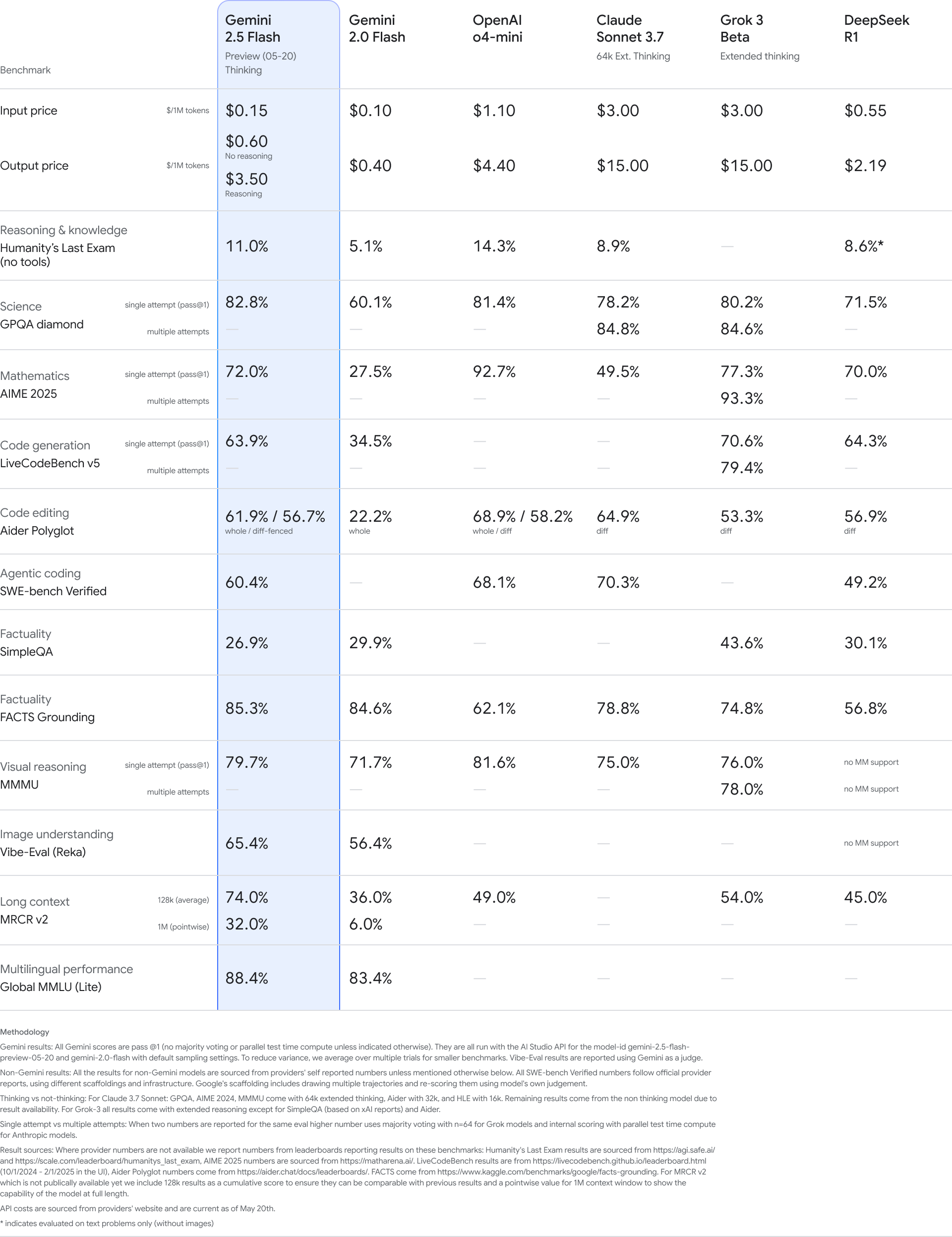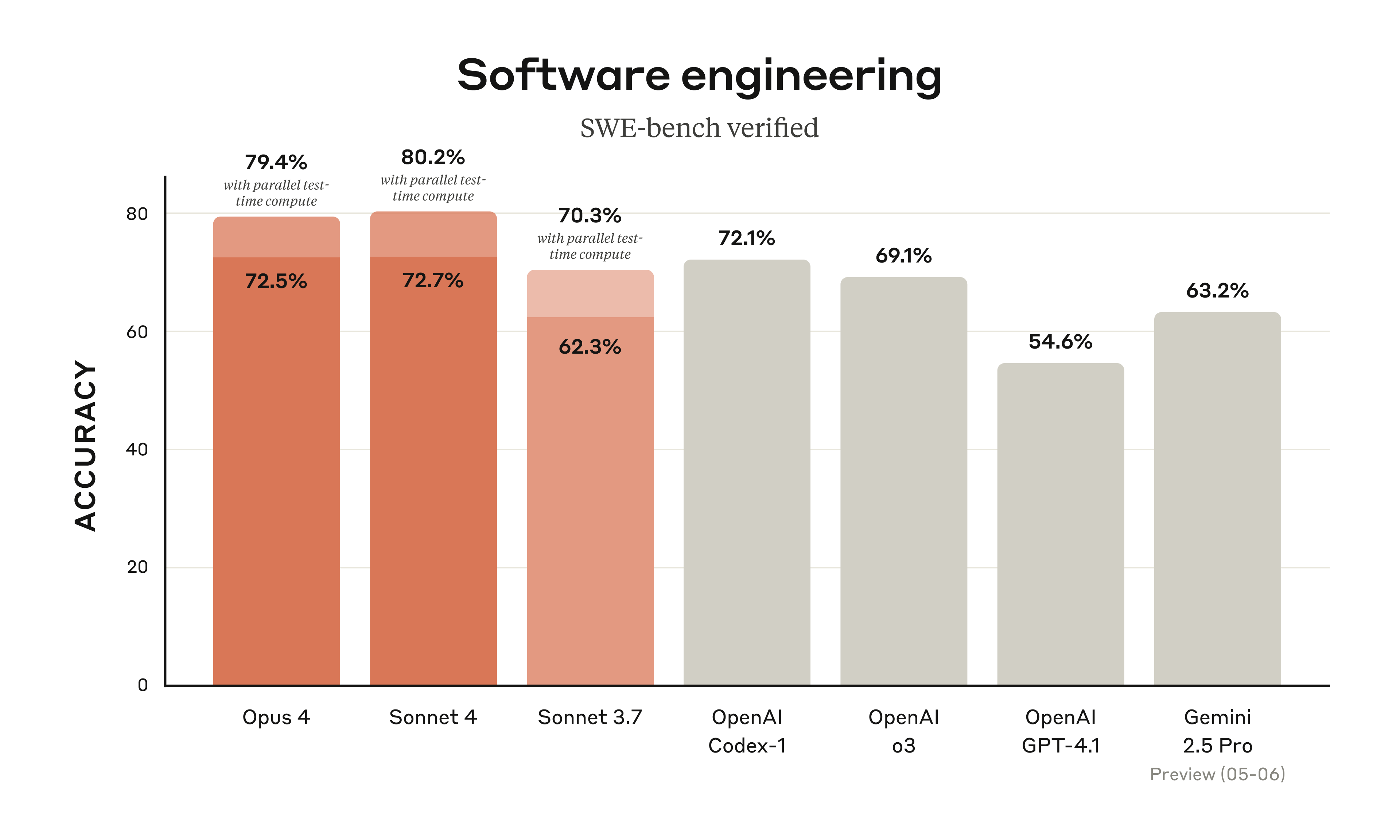
Anthropic has launched its next-generation AI models, Claude Opus 4 and Claude Sonnet 4, with a strong emphasis on advancements in coding, complex reasoning, and building robust AI agents. Opus 4 is presented as the leading coding model, demonstrating sustained performance on challenging, long-duration tasks, evidenced by top results on benchmarks like SWE-bench (72.5%) and Terminal-bench (43.2%). Sonnet 4 significantly upgrades Sonnet 3.7, offering enhanced coding and reasoning with improved instruction following. Key new capabilities across both models include extended thinking with tool use (like web search), parallel tool execution, and enhanced memory features when provided access to local files. The article also announces the general availability of Claude Code, offering seamless integration via IDE extensions (VS Code, JetBrains) and a SDK for custom agents, including GitHub integration. New API capabilities like code execution, MCP connector, Files API, and prompt caching further empower developers. The models are available on multiple platforms including Claude.ai, Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI, with pricing detailed.