大家好,欢迎阅读 BestBlogs.dev 第 60 期 AI 精选。
本周,开源大模型的实用化演进再次提速。DeepSeek 与字节跳动相继发布新品,带来了可切换推理模式与原生 512K 超长上下文等创新特性。在开发者生态中,上下文工程的讨论从理论走向实践,JSON 提示词与系统性评估正成为构建可靠 AI 应用的基石。产品层面,从手机通用智能体到 AI 陪伴硬件,越来越多贴近真实生活场景的应用开始涌现,而行业领袖们则在深度访谈中,为 AI 时代的创业与组织变革指明了方向。
🚀 模型与研究亮点
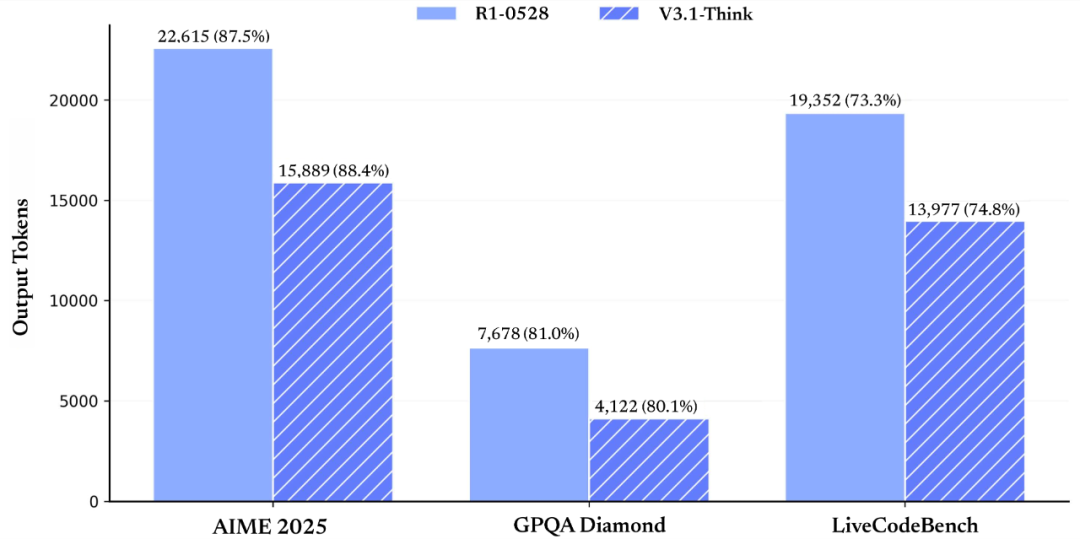
- 🧠 DeepSeek 发布 V3.1 模型,其创新的混合推理架构,可自由切换思考与非思考模式,在增强智能体任务表现的同时,显著提升了思考效率。
- 📖 字节跳动开源 Seed-OSS 大模型,原生支持 512K 超长上下文,是当前主流模型的 4 倍,并引入独特的“思考预算”机制来控制推理深度。
- 🎨 通义千问开源 Qwen-Image-Edit 模型,通过语义与外观双重控制,成功将文本渲染能力拓展至图像编辑任务,实现了精准的文字与图像修改。
- ⚙️ 一篇技术长文系统性地剖析了深度神经网络训练的五大核心步骤,内容覆盖从前向传播、损失函数到反向传播与优化器的完整流程。
- 📜 从 GPT-2 到 gpt-oss ,一篇深度解读文章追溯了 OpenAI 开放模型的架构演变,详细解析了混合专家模型、旋转位置嵌入等关键技术。
- 🤔 大模型如何推理?DeepMind 首席科学家在斯坦福 CS25 课程中指出,推理的关键在于生成一系列中间 token,而强化学习是有效激发该能力的强大途径。
🛠️ 开发与工具精粹
- 👑 Chroma 的 CEO 提出“RAG 已死,上下文工程为王”,他认为随着 AI 从聊天机器人发展为复杂智能体,结构化的上下文管理至关重要。
- 🧐 一篇文章以编译原理为基础,深刻阐述了从提示词工程到上下文工程,再到 Anthropic 的 Think Tool 的演进,预示着 AI 编程正走向更严格的形式化。
- 📝 一份终极指南详细介绍了 JSON 提示词的巨大优势,指出其结构化输入能有效降低歧义,是构建可靠、可扩展 AI 系统的关键技术。
- ✅ 一篇超实用的文章手把手教你如何搭建 AI 产品的评估系统 Evals,并将其比作 AI 的驾照考试,是确保系统持续创造价值的关键。
- 🏗️ 当代码遇上大模型,智能编程助手的架构应如何设计?一篇文章深入探讨了上下文感知、记忆管理和多 Agent 协作等工程实践。
- 💻 一份 Claude Code 完全指南,详细介绍了其原生终端集成、自定义斜杠命令、多角色协作等核心优势,并为国内用户提供了两种实用方案。
💡 产品与设计洞见
- 🎨 一款名为 Nano Banana 的神秘 AI 绘图模型,在盲测中展现了惊人的人物一致性,其效果远超现有主流模型,被誉为新一代王者。
- 📱 智谱发布全球首个手机通用智能体 AutoGLM ,通过云端执行模式,为用户提供可操控云手机或云电脑的跨应用自动化处理能力。
- 🧸 一款获得朱啸虎投资的 AI 陪伴硬件“芙崽”,通过毛绒外观和共享记忆系统,旨在成为 Z 世代的数字宠物,聚焦情绪价值以缓解孤独感。
- ✍️ YouMind 创始人玉伯在对谈中分享了他的 AI 创作工具,其核心理念是从知识管理转向项目制创作,并提出了“剪藏即点赞”的独特观点。
- 🌐 Perplexity 的 CEO 认为 AI 硬件是伪需求,真正的革命不在于新设备,而在于浏览器,因为它是获取用户全面上下文的终极载体。
- 📱 Google Pixel 10 系列发布,其完全自研的 Tensor G5 芯片与 Gemini 端侧模型的深度整合,展现了手机从被动工具向主动助理的转变。
📰 资讯与报告前瞻
- 🚀 吴恩达 在最新分享中指出,能动 AI 实现的最大障碍是缺乏懂得如何通过严谨评估来驱动系统迭代的人才,未来属于小而精的团队。
- 🧠 OpenAI 联创 Greg Brockman 回应 GPT-5 争议,他认为模型提升感知不明显是因消费级任务饱和,而在企业级复杂任务上已有卓越表现。
- 📊 美国知名风投 BVP 发布年度 AI 报告,指出记忆与上下文将是新的护城河,并对 AI 基础设施、开发者平台等五大方向的演进做出预测。
- 📈 一期大模型季报播客指出,头部模型公司正走向分化,成功 AI 产品的关键在于提供 L4 级别的惊叹时刻体验,以构建非技术性壁垒。
- 🚗 理想汽车创始人李想 与罗永浩 展开四小时马拉松访谈,首次公开讲述其 25 年创业之路,并分享了对商业、人才与 AI 的深刻洞察。
- 🇨🇳 一份月度技术观察报告指出,随着国产开源模型的崛起,开源已变成中国的主场,中美在语言模型领域已进入同等水平竞争。
希望本期的精选内容能为您带来启发。我们下周再见!